Page History
| Section | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Design ScopeGForge itemsPlease visit the LexEVS 5.1 Scope document found at: https://wiki.nci.nih.gov/display/EVS/LexEVS+5.1+Scope+document Solution ArchitectureProposed technical solution to satisfy the following requirements:
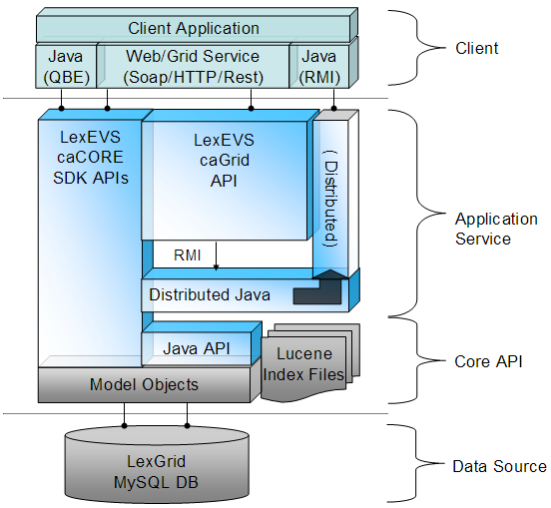
High Level ArchitectureThe LexEVS 5.1 infrastructure exhibits an n-tiered architecture with client interfaces, server components, domain objects, data sources, and back-end systems (Figure 1.1). This n-tiered system divides tasks or requests among different servers and data stores. This isolates the client from the details of where and how data is retrieved from different data stores. The system also performs common tasks such as logging and provides a level of security for protected content. Clients (browsers, applications) receive information through designated application programming interfaces (APIs). Java applications communicate with back-end objects via domain objects packaged within the client.jar. Non-Java applications can communicate via SOAP (Simple Object Access Protocol) or REST (Representational State Transfer) services. Most of the LexEVS API infrastructure is written in the Java programming language and leverages reusable, third-party components. The service infrastructure is composed of the following layers: Application Service layer - accepts incoming requests from all public interfaces and translates them, as required, to Java calls in terms of the native LexEVS API. Non-SDK queries are invoked against the Distributed LexEVS API, which handles client authentication and acts as proxy to invoke the equivalent function against the LexEVS core Java API. The caGrid and SDK-generated services are optionally run in an application server separate from the Distributed LexEVS API. Core API layer - underpins all LexEVS API requests. Search of pre-populated Lucene index files is used to evaluate query results before incurring cost of database access. Access to the LexGrid database is performed as required to populate returned objects using pooled connections. Data Source layer---is responsible for storage and access to all data required to represent the objects returned through API invocation. High Level Design Diagram
Figure 1.1 - High Level Diagram Query Performance EnhancementsLucene - Lazy Document LoadingLucene is very fast as a search engine. Given a text string, Lucene can find matching documents in huge indexes very fast. This is the purpose and strength of Lucene. Lucene is not, however, a database. Retrieving information from the documents that the search found as 'hits' is slow. Consider this scenario: A user searches for 'heart' in the NCI MetaThesaurus. When Lucene does its search, it will return probably 50,000+ 'hits'. This search is done very fast. LexEVS previously would retrieve all of those documents to populate the ResolvedConceptReference. Retrieving this many documents from Lucene is slow. The solution is to is lazy load the documents as needed. After the Lucene search is complete, we only store the Document Id. Then, when information from the document is needed, it is retrieved from the document. This is helpful in Iterator-type scenarios, where retrieval can be done one at a time. Update to Lucene 2.4 CodeAs we move forward, it is important to keep current with the latest Lucene API. Not only is this important for performance reasons -- it will limit our ability to upgrade our Lucene dependencies if we rely on Searching - Plug-in Search FrameworkWe advertise our Searches as being 'extensions', but in reality it is very difficult (or impossible) for a use to create a plug-in type Search. The Interface org.LexGrid.LexBIG.Extensions.Query.Search will be introduced. The purpose of this interface is to give users a plug-in type Interface to implement different search strategies. This interface will accept Sorting - Plug-in Sort FrameworkAs with Searching, Sort algorithms are not currently easily extended. A well defined and 'Extension-ready' interface would allow users to add additional search functionality on demand, without rebuilding or recompiling. The existing Interface org.LexGrid.LexBIG.Extensions.Query.Search will be expanded to allow for easy implementation and flexibility, allowing rapid creation of new Sort Algorithms and techniques. SQL - SQL query optimizations to increase database performanceJoin EntityDescription when building AssociatedConcepts Furthermore, this will allow the 'EntityDescription' to be available without requiring the actual 'CodedEntry' to be resolved. For most usescases, this should enable users to resolve Graphs with 'CodedEntryDepth=0'. Avoiding any resolving of the CodedEntry will keep resolve times to a minimum. Join EntryState when building CodedEntry NCI MetaThesauraus Content (RRF)Loads of the NCI MetaThesaurus RRF formatted data into the LexGrid model require a number of loader adjustments in order to accurately reflect the state of the data as it exists in the current RRF files. No model or API changes will be necessary to accommodate the data; changes will be made directly to to the loader. Value Domain SupportThe LexEVS Value Domain and Pick List service will provide ability to load Value Domain and Pick List Definitions into LexGrid repository and provides ability to apply user restrictions and dynamically resolve the definitions during run time. Both Value Domain and Pick List service are integrated part of LexEVS core API. The LexEVS Value Domain and Pick List service will provide programmatic access to load Value Domain and Pick List Definitions using the domain objects that are available via the LexGrid logical model. The LexEVS Value Domain and Pick List service will provide ability to apply certain user restrictions (ex: pickListId, valueDomain URI etc) and dynamically resolve the Value Domain and Pick List definitions during the run time The LexEVS Value Domain and Pick List Service meant to expose the API particularly for the Value Domain and Pick List elements of the LexGrid Logical Model. For more information on LexGrid model see http://informatics.mayo.edu\\ Improved Loader FrameworkLexEVS already provides a set of loaders within an existing legacy framework which has served LexEVS developers well over the years. But as LexEVS has gained users, and requests for new loaders has grown , it was decided that a new Loader Framework should be developed. The new framework: provides classes and interfaces that are more modular and easier to extend; improved loader performance; allows dynamic loading of new loaders; is built upon proven open source technologies such as SpringBatch and Hibernate, and finally, the new Loader Framework code is completely independent of the current loader code in LexEVS so there will be no impact to current loaders. Cross product dependenciesInclude a link to the Core Product Dependency Matrix. Changes in technologyInclude any new dependencies in the Core Product Dependency Matrix and summarize them here.
AssumptionsList any assumptions. Risks
Detailed DesignSpecify how the solution architecture will satisfy the requirements. This should include high level descriptions of program logic (for example in structured English), identifying container services to be used, and so on. Query Performance EnhancementsLucene Lazy LoadingBackgroud - Lucene Documents For example, an index of People may be indexed in Lucene as:
LexEVS stores information about Entities in this way. Property names and values, as well as Qualifiers, Language, and various other information about the Entity are held in Lucene indexes. Backgroud - Querying Lucene Lucene provides a Query mechanism to search through the indexed documents. Given a search query, Lucene will provide the Document id and the score of the match (Lucene assigns every match a 'score', depending on the strength of the match given the query). So, if the above index is queried for "First Name = Jane AND Last Name = Doe", the result will be the Document id of the match (2), and the score of the match (a float number, usually between 1 and 10). Notice that none of the other information is returned, such as Sex or Age. It is useful for that extra information to be there, because if it exists in the Lucene indexes we do not have to make a database query for it. BUT, retrieving data from Lucene Documents is expensive, just as retrieving data from a database would be.
If a user constructs a Query (Name = Heart*), the query will return with the matching Document ids (1 and 2). Previously, LexEVS would immediately retrieve the 'Code' and 'Name' fields from the matches, and use them to construct the results that would be ultimately returned to the user. This does not scale well, especially for general queries in large ontologies. In a large ontology, a Query of (Name = Heart*) may match tens of thousands of Documents. Retrieving the information from all these Documents is a significant performance concern. Instead of retrieving the information up front, LexEVS will simply store the Document id for later use. When this information is actually needed by the user (for example, the information needs to be displayed), it is retrieved on demand. SearchingTo allow users to plug in custom search algorithms, the LexEVS Extension framework needed to be extended to include Searches. The org.LexGrid.LexBIG.Extensions.Extendable.Search interface consists of one method to be implemented:
This enables the user to construct any type of Query given search text. Wildcards may be added, search terms may be grouped, etc. Algorithms More precice DoubleMetaphoneQuery For example, the Metaphone computed value for "Breast" and "Prostrate" is the same. Given the search term "Breast", both "Breast" and "Prostrate" will match with exactly the same score. Technically, this is correct behavior, but to the end user this is not desirable. To overcome this, we have introduced a new query, WeightedDoubleMetaphoneQuery. WeightedDoubleMetaphoneQuery Algorithm:
Case-insensitive substring SubStringSearch - This algorithm is intended to find substrings within a large string. For example: Also, a leading and trailing wildcard will be added, so Algorithm:
SortingSorting matched results is important part of interacting with the LexEVS API. Allowing users to plug in customized Sort algorithms helps LexEVS to be more flexible to more groups of users. To implement a Sorting algorithm, a user must implement the org.LexGrid.LexBIG.Extensions.Extendable.Sort Interface.
As described earlier, all results are by default sorted by Lucene score, so if we limit the result set to the top 3, the result is:
Algorithm:
SQL OptimizationsThe n+1 SELECTS ProblemThe n+1 SELECTS Problem refers to how information can optimally be retrieved from the database, preferably using as few queries as possible. This is desirable because:
To avoid this, a JOIN query can be used. The n+1 SELECTS Problem ExampleGiven two database tables, retrieve the Code, Name, and Qualifier for each Code Table Codes
Table Qualifiers
Results in:
To get the Qualifiers, separate SELECTs must be used for each.
This sequence results in 1 Query to retrieve the data from the Codes table, and then n Queries from the Qualifiers table. This results in n+1 total Queries. The n+1 SELECTS Problem Example (Solution)Given two database tables, retrieve the Code, Name, and Qualifier for each Code Table Codes
Table Qualifiers
Results in:
Because of the JOIN, only one Query is needed to retrieve all of the data from the database. Although sometimes obvious, n+1 queries can remain in a system undetected until scaling problems are noticed. In LexEVS there were 3 n+1 SELECT queries fixed:
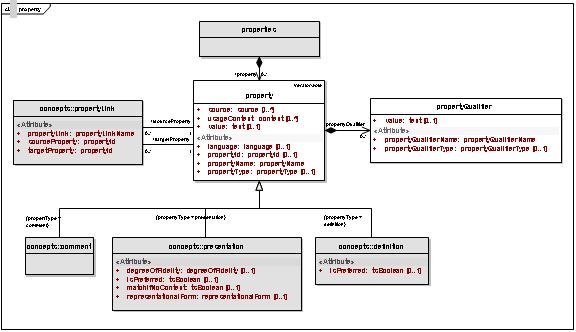
Metathesauraus Content (RRF)Loads of the NCI MetaThesaurus RRF formatted data into the LexGrid model require a number of adjustments in order to accurately reflect the state of the data as it exists in the current RRF files. Data Model ElementsMost data elements will be loaded as either properties or property qualifiers:
A few will be loaded as qualifiers to associations. Retrieval and API DocumentationNo new API retrieval methods will be implemented in the scope of LexEVS 5.1. However, some may be required in the scope of 6.0 for any mapping elements implemented as new model elements or model extensions to LexGrid. No changes to user interfaces will occur. Service methods for loading these elements will be consistent with the new Spring Batch loader framework. MRREL.RRF FileProblem: REL and RELA column elements from the RRF source need to be connected. Requirement: A single relationship should be loaded for a REL/RELA combination for a particular SAB between two CUIs. Solution: Since RELA type RRF elements have been defined as relationship names specific to sources and not independent relationships themselves, these elements will be loaded as association qualifiers in the LexGrid model. Problem and Requirement: User is unable to distinguish individual relationships from one source or another. The same association "entity" exists only once but has two "source" qualifiers. Proposed Solution: Propose AUI to AUI - the way CUI to CUI are currently handled in the implementation. Load supporting column elements from MRREL.RRF including contents of: These will be available as elements of the overriding Metathesaurus Association and loaded as association qualifiers Problem: Self Referencing Relationships (CUI1 = CUI2) cannot be fully represented in our model. Previously, these were loaded as PropertyLinks. This fit into the LexEVS model well, but left out important RRF information. Most notably, PropertyLinks cannot contain Qualifiers like normal relations can. Because of the increased number of Qualifiers that are required to be placed on relations, much information would be lost representing these relations as PropertyLinks Solution: Do not treat a CUI1 = CUI2 relationships differently than a CUI1 != CUI2 relationship. For API and query purposes, qualify these relationships with a 'selfReferencing=true' Qualifier. In this way, we can still avoid cycles in the API, but maintain all relevant Qualifier information in the relation. MRSAT.RRFProblem: MRSAT.RRF is not loaded but only accessed for given preferred term algorithms. This data should be loaded as concept properties (STYPE=CUI), properties on properties (STYPE=AUI, SAUI, CODE, SCUI, SDUI), qualifiers on associations (STYPE=RUI,SRUI). Some complexity may arise as concept properties can have additional qualifiers, but property-properties cannot and association-qualifiers cannot. Requirement: If the STYPE is something other than RUI or SRUI, you can load CUI - We use this as the entityCode and is loaded as such in the table. METAUI - load as a propertyQualifier (name=METAUI, value) STYPE - load as a propertyQualifier (name=STYPE, value) ATUI - load as propertyId ATN - load as property name SAB - load as a propertyQualifier (typeName=source) ATV- load as a propertyValue SUPPRESS - load as propertyQualifier if value != N MRRANK.RRFProblem: SAB specific ranking of representational form in MRRANK is not exposed to the user (used in an underlying ranking and specifying of preferred presentations for a given concept) Requirement: Load elements of MRRANK so that they are available to the user. Proposed Solution: Load MRRANK as property qualifier on Presentation type property with the property Name of "mrrank." Retrieval: Available in current LexEVS api MRSAB.RRFProblem: MRSAB.RRF file data is not loaded or is otherwise unavailable to the user. Requirement: Load MRSAB.RRF file data as metadata Implemented Solution: Entire content of each row of MRSAB file is loaded as metadata to an external xml file with tags created from column names and value inserted between tags as is appropriate MRMAP.RRF, MRSMAP.RRFProblem: MRMAP.RRF source load is not supported in current load. Currently this RRF file is not populated in NCI Metathesaurus distributions. Mapping is not explicitly supported in the LexGrid Model. Requirement: Load MRMAP data. Solution: To be evaluated for a load to current model elements or possible new model mapping elements. The general agreement is that this is more appropriately implemented in 6.0. MRHIER.RRFProblem: HCD is loaded as a property on the presentation but the SAB isn't associated with it so we do not know the source of the HCD. (only look at row that has HCD field populated) Requirement: These elements need to be loaded and available from the LexEVS api Solution: Load HCD associated field SAB as property qualifier when HCD is present. Load PTR as property. MRDOC.RRFProblem: MRDOC contains metadata unavailable to the user. It is not loaded by LexEVS. Requirement: This metadata will be made available to the user. Solution: MRDOC's column names and content will be processed as tag/value mappings to a metadata file. MRDEF.RRFProblem: Some values from each row are not loaded by LexEVS. Requirement: AUI should be loaded to connect it with the presentation ATUI, SUPPRESS, CVF, SATAUI, column values will be loaded as property qualifiers on the Definition type property derived from MRDEF column. MRCONSO.RRFProblem: Some elements from the columns of MRCONSO.RRF are not loaded by LexEVS. Requirement: Load LUI, SUI, SAUI, SDUI, SUPPRESS, CVS fields and expose to the user. Solution: All noted values will be loaded as property qualifiers. Value Domain Support
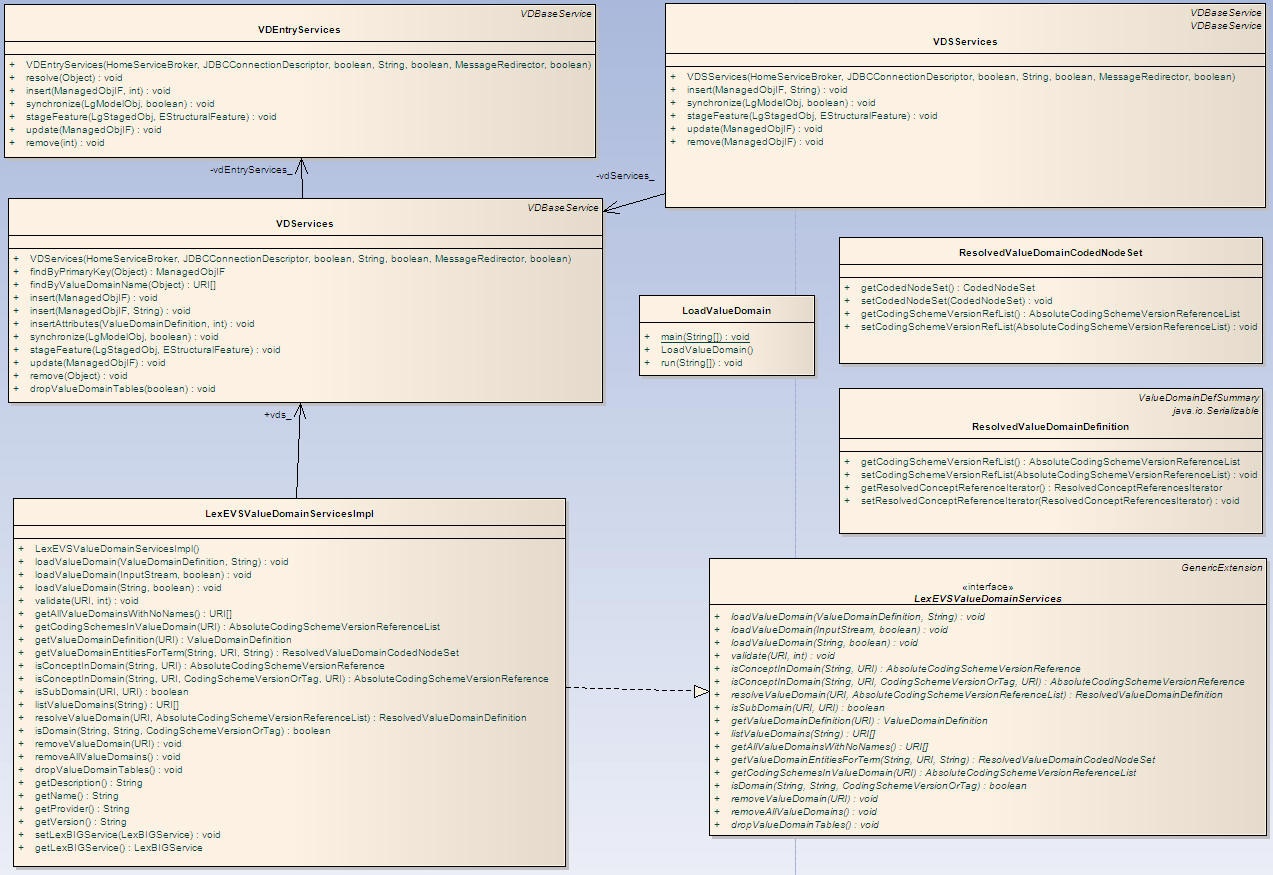
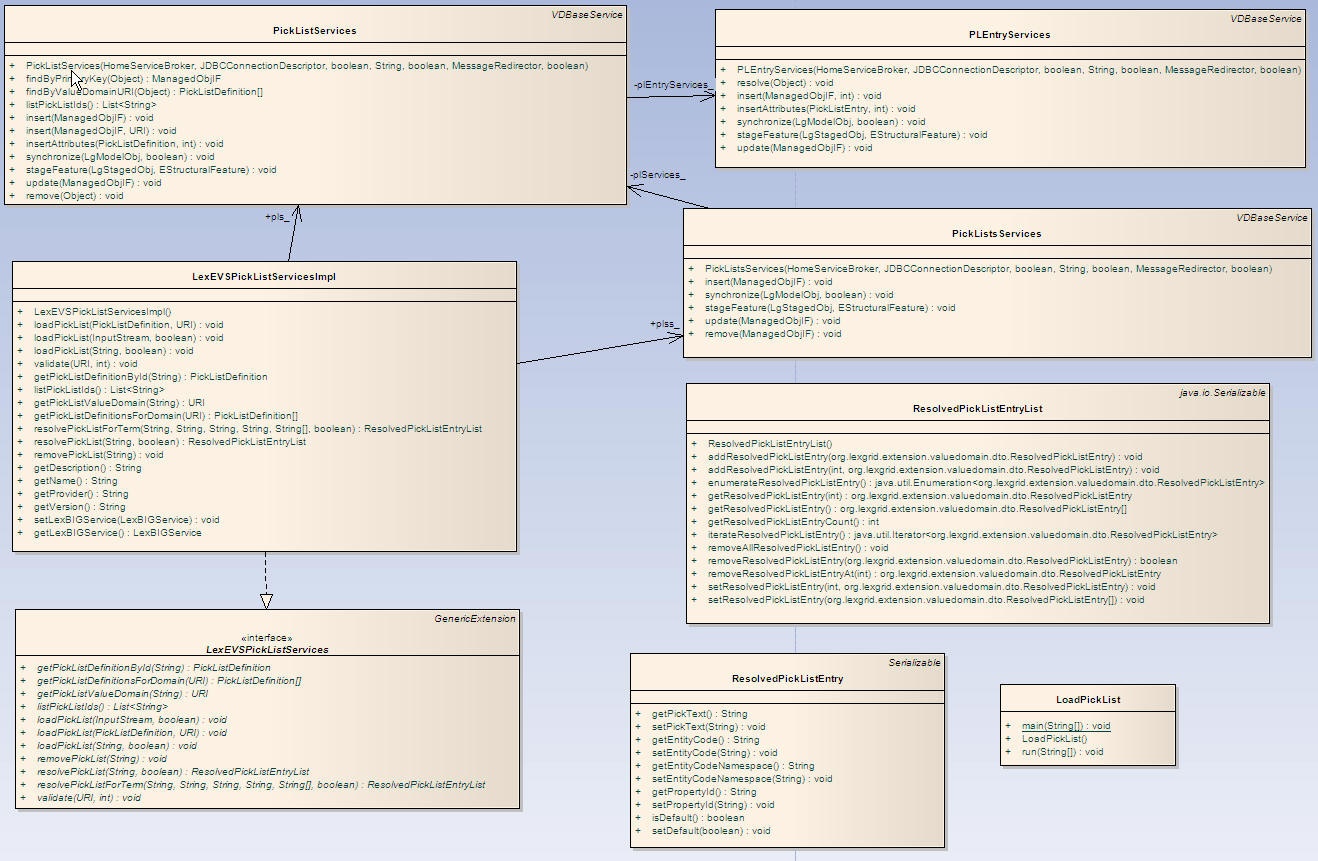
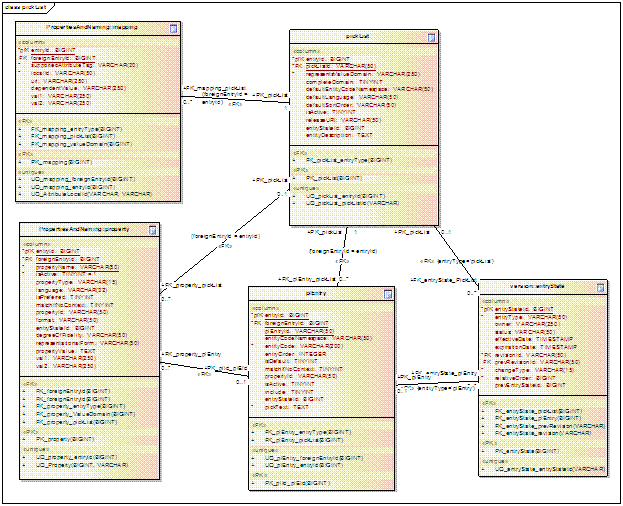
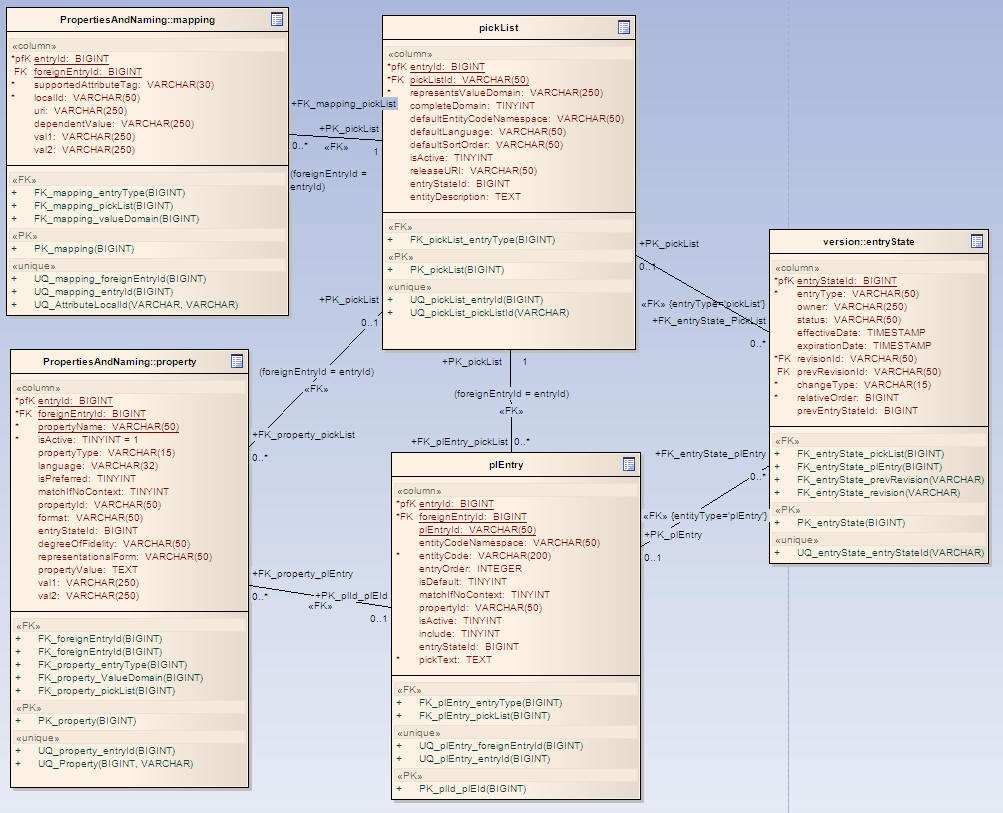
ScopeThe LexEVS Value Domain and Pick List service will provide programmatic access to load Value Domain and Pick List Definitions using the domain objects that are available via the LexGrid logical model. The LexEVS Value Domain and Pick List service will provide ability to apply certain user restrictions (ex: pickListId, valueDomain URI etc) and dynamically resolve the Value Domain and Pick List definitions during the run time. ArchitectureThe LexEVS Value Domain and Pick List Service meant to expose the API particularly for the Value Domain and Pick List elements of the LexGrid Logical Model. For more information on LexGrid model see http://informatics.mayo.edu/ LexEVS Value Domain and Pick List Service Class DiagramCommon Services Class DiagramThese are the classes that are used commonly across Value Domain and Pick List implementation.
Value Domain Class DiagramClasses that implements LexEVS Value Domain API
Pick List Class DiagramClasses that implements LexEVS Pick List API
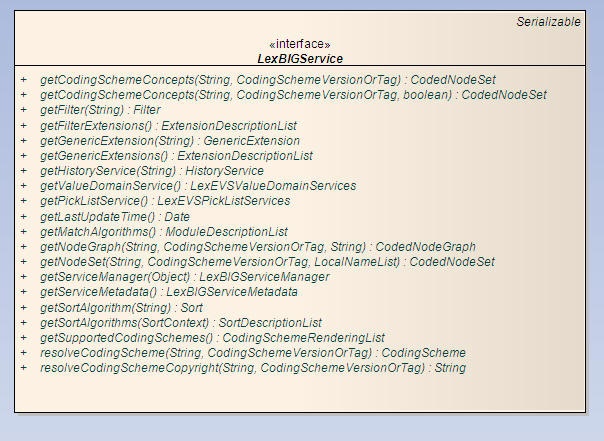
LexBIG Services Class DiagramAn interface to LexEVS Value Domain and Pick List Services could be obtained using an instance of LexBigService.
Main Service APILexBIG APIAn interface to LexEVS Value Domain and Pick List Services could be obtained using an instance of LexBigService.
LexEVS Value Domain Service APIh7. Loading Value Domain There are three methods that could be used to load Value Domain Definitions :
Validate XML resources
Query Value Domain
Remove Value Domain Definition
Drop Value Domain tables
LexEVS Pick List Service APILoading Pick ListThere are three methods that could be used to load Pick List Definitions :
Validate XML resources
Query Pick List
Remove Pick List Definition
Resolved Value Domain ObjectsResolvedValueDomainCodedNodeSetContains Coding Scheme Version reference list that was used to resolve the Value Domain and the CodedNodeSet. ResolvedValueDomainDefinitionA resolved Value Domain Definition containing the Coding Scheme Version reference list that was used to resolve the Value Domain and an iterator for resolved concepts. Resolved Pick List ObjectsResolvedPickListEntryContains resolved Pick List Entry Nodes ResolvedPickListEntryListContains the list of resolved Pick List Entries. Also provides helpful features to add, remove, enumerate Pick List Entries. Error HandlingBoth LexEVS Value Domain and Pick List services uses org.LexGrid.LexBIG.Impl.loaders.MessageDirector to direct all fatal, error, warning, info messages with appropriate messages to the LexBIG log files in the 'log' folder of LexEVS install directory. Along with MessageDirector, the services will also make use of org.LexGrid.LexBIG.exception.LBException to throw any fatal and error messages to the log file as well as to console. Load ScriptsScripts to load Value Domain and Pick List Definitions into LexEVS system will be located under 'Admin' folder of LexEVS install directory. This loader scripts will only load data in XML file that is in LexGrid format. Value Domain LoaderLoadValueDomain.bat for Windows environment and LoadValueDomain.sh for Unix environment.
Example:sh LoadValueDomain.sh -in "file:///path/to/file.xml|\path\to\file.xml" Pick List LoaderLoadPickList.bat for Windows environment and LoadPickList.sh for Unix environment.
Example:sh LoadPickList.sh -in "file:///path/to/file.xml|\path\to\file.xml" Sample XML filesValue Domain DefinitionsBelow is a sample XML file containing Value Domain Definitions in LexGrid format that can be loaded using LexEVS Value Domain Service.
Pick List DefinitionsBelow is a sample XML file containing Pick List Definitions in LexGrid format that can be loaded using LexEVS Pick List Service.
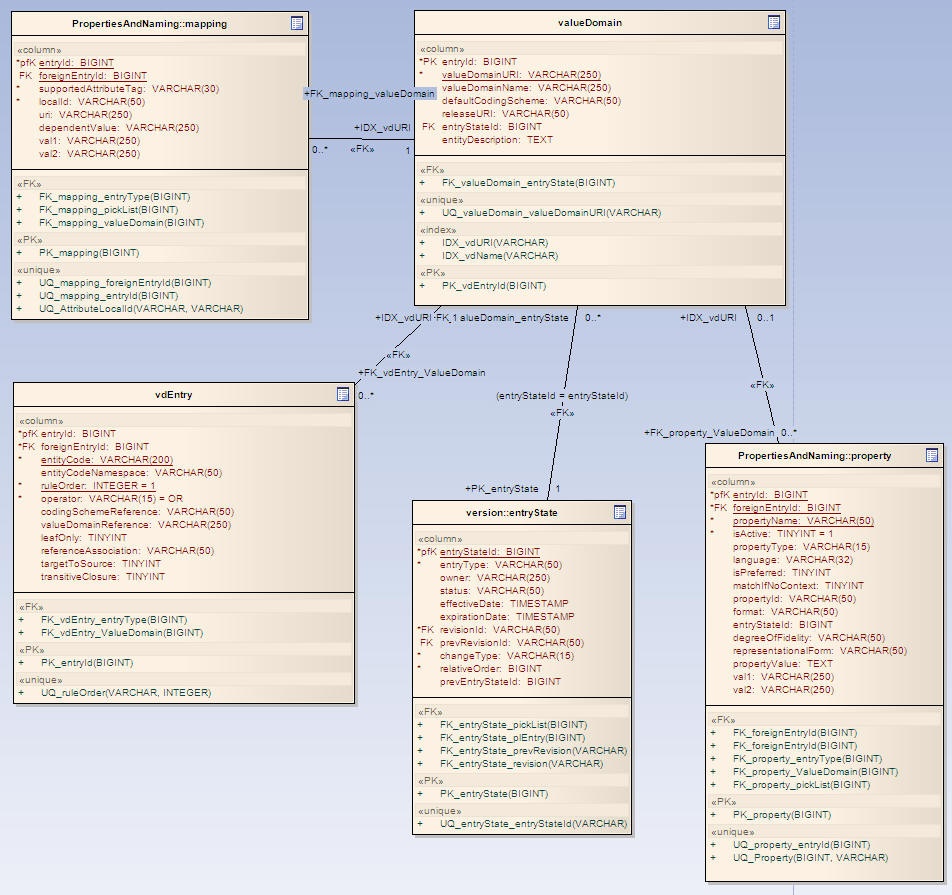
Database structureValue Domain Tables
Pick List Tables
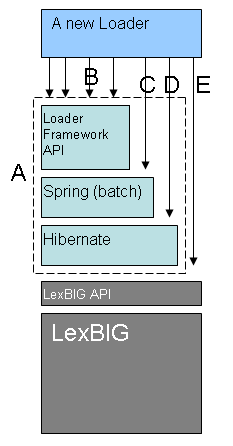
Installation / PackagingBoth LexEVS Value Domain and Pick List services are integrated part of core LexEVS API and will be packaged and installed with other LexEVS services. System TestingValue Domain ServiceThe System test case for the LexEVS Value Domain service is performed using the JUnit test suite: org.LexGrid.LexBIG.Impl.testUtility.VDAllTests This test suite will be run as part of regular LexEVS test suites AllTestsAllConfigs and AllTestsNormalConfigs. Pick List ServiceThe System test case for the LexEVS Value Domain service is performed using the JUnit test suite: org.LexGrid.LexBIG.Impl.testUtility.PickListAllTests This test suite will be run as part of regular LexEVS test suites AllTestsAllConfigs and AllTestsNormalConfigs. Improved Loader FrameworkDocument PurposeThis document provides the detailed design and implementation of LexBIG Enterprise Vocabulary Service (LexEVS) Loader Framework Extension. It is also the goal of this document to provide enough information to allow those persons wishing to create their own loaders can do so. This document will also assume the reader is already familiar with the LexEVS software. Implementation OverviewDescriptionThe LexEVS software already provides a set of loaders within an existing legacy framework which served LexEVS developers well over many years. But as LexEVS has gained users, and requests for new loaders has grown , it was decided that a new loader framework should be developed that would: (1) be easier to extend (2) provide improved performance (3) dynamic loading of new loaders (4) take advantage of proven open source components such as Spring Batch and Hibernate. Specifically, this development work addresses "TASK 6 - IMPROVE LEXEVS LOADING FRAMEWORK" in the National Cancer Institute (NCI) Statement of Work (SOW) document (reference ?????). Also, this Framework is completely independent of the current loader code so there is no impact to current loaders. ScopeThe LexEVS Loader Framework will provide a way for LexEVS developers to write new loaders and have them recognized dynamically by the LexEVS code. Also the framework will provide help to loader developers in the form of utility classes and interfaces. ArchitectureThe LexEVS Loaders Framework extend the functionality of LexBIG 5.0 . For more information on LexBIG, see https://cabig-kc.nci.nih.gov/Vocab/KC/index.php/LexEVS_Version_5.0 High Level Overview Figure 1 (below) shows the major components of the Loader Framework (A) in relation to a hypothetical new loader and what expected API usage would be. Ideally, the new loader can find make most if its API calls through the utilities provided by the Loader Framework API (B). Some work will need to be done with Spring (C) such as configuration of a Spring config file. Also it may or may not be necessary for a loader to use Hibernate (D) or use the LexBIG API (E). However, again, the hope is that much of the work a new loader may need to do can be accomplished by the Loader Framework API. The Loader Framework utilizes Spring Batch for managing its Java objects to improve performance and Hibernate provides the mapping to the LexGrid database.
Assumptions
Dependencies
Issues
Third Party Tools
Implementation ContentsDevelopment and Build EnvironmentThe Loader Framework code is available in the NCI Subversion (SVN) repository. It is comprised of three Framework projects. Also at the time of this writing there are three projects in the repository that utilize the Loader Framework. These projects utilize Maven for build and dependency management. Loader Framework Projects
Loader Proejcts Using the New Framework
Maven The above projects are built and managed by Maven. How to Use the Loader Framework: A RoadmapSo you want to write a loader and use the Loader Framework. What are the key considerations?
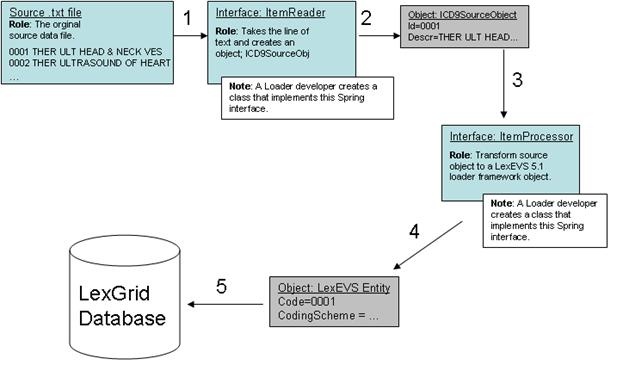
An example may help in understanding the Framework. Our discussion will refer to figure 2 below. Lets say we are writing a loader to load the ICD-9-CM codes and their description which are contained in a text file. We know we'll need a data structure to hold the data after we've read it so we have a class:
Enter Spring. The Loader Framework uses Spring Batch to manage the reading, processing and writing of data. Spring provides classes and interfaces to help do this work and the Loader Framework also provides utilities to help loader developers. In our example, we will write a class that will use the Spring ItemReader interface. It will take a line of text and return an ICD9SourceObject (1 and 2). Next we'll want to process that data into a LexEVS object such as an Entity object. So we'll write class that implements Spring's ItemProcessor interface. It will take our ICD9SourceObject and output a LexEVS Entity object (3,4). Finally, we'll want to write the data to the database (5). Note that the LexEVS model objects provided in the Loader Framework are generated by Hibernate and utilize Hibernate to write the data to the database. This will free us from having to write SQL.
Spring ItemReader/ItemProcessor Maven Set up The projects containing the Loader Framework (PersistanceLayer , loader-framework , and loader-framework-core) use Maven for dependency management and build. You will still use Eclipse as your IDE and code repository but you will need to install a Maven plugin for Eclipse which can be found at: http://m2eclipse.sonatype.org/ After the plugin is installed you'll need to provide a URL and userid/password to a Maven repository on a server (which manages your dependencies or dependent jar files). Ours here at Mayo is: Once Maven is configured you can import the Loader Framework classes from SVN. Upon doing that you will most likely see build errors about missing jars. Resolve those by right clicking on the project with errors, select 'Maven', and 'Resolve Dependencies'. This will pull the dependant jars from the Maven repository into your local environment. To build a Maven project, right click on the project, select 'Maven', then select 'assembly:assembly'. Eclipse Project Set up When loader developers create a new loader project in Eclipse it is recommended they follow the Maven directory structure. By following this convention Maven can build the project and find the test cases. From the Maven documentation:
For more information on the Maven project see: Configure your Spring Config (myLoader.xml) Spring is a lightweight bean management container and among other things it contains a batch function which is utilized by the Loader Framework. A loader using the framework will need to work closely with Spring Batch and the way it does that is through Spring's configuration file where you configure beans (your loader code) and how the loader code should be utilized by Spring Batch (by configuring a Job, Step and other Spring Batch stuff in the spring config file). What follows is a brief overview of those tags related to the LoaderFramework. For more detail please see the Spring documentation: http://static.springsource.org/spring-batch/reference/html/index.html.
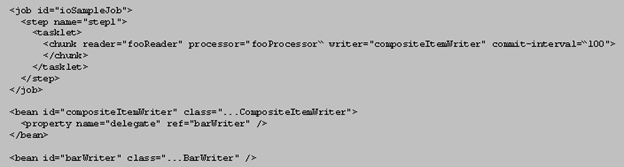
Beans The 'beans:beans' tag is the all-encompassing tag. You define all your other tags in here. You can also define an import within this tag to import an external Spring config file. Not shown in figure 3. Bean Use these tags, 'beans:bean', to define the beans to be managed by the Spring container by specifying the packaged qualified class name. You can also specify inititialization values and set bean properties within these tags.
Job The 'job' tag is the main unit of work. The job is comprised of one or more steps that define the work to be done. Other advanced and interesting things can be done within the Job such as using 'split' and 'flow' tags to indicate work that can be done in parellel steps to improve performance.
Step One or more step tags make up a job and can very from simple to complex in content. Among other things, you can specify which step should be executed next. Tasklet You can do anything you want within a Tasklet such as sending an email or a LexBIG function such as indexing. You're not limited to just database operations. The Spring documentation also has this to say about Tasklets:
Chunk Spring documentation says it best:
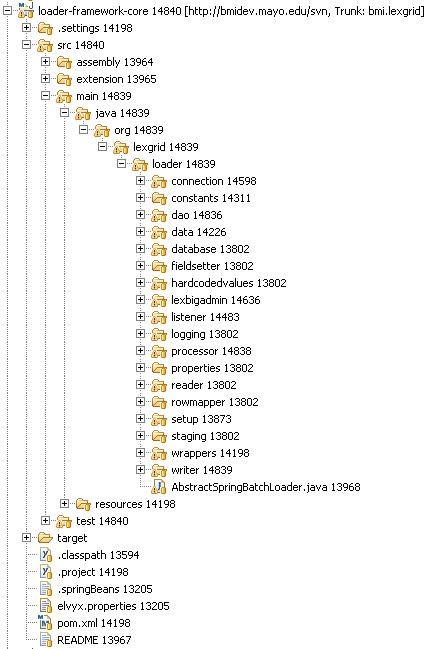
Reader An attribute of the chunk tag. Here is the class that you defined implementing the Spring ItemReader interface to read data from your data file and create domain-specific objects. Processor Another attribute of the chunk tag. This is the class that implements the ItemProcessor interface where other manipulations of the domain objects take place. In the case of the Loader Framework we create LexGrid model objects from the domain objects so that they can be written to the database via Hibernate. Note that this is not a required attribute. In theory if you had a data source you could read from such that you could create LexBIG object immediately you would not have need of a processor. In practice this is most likely not be the case. You will need to work with the data to get it into LexBIG objects. Writer Attribute of the chunk tag. This class will implement the Spring interface ItemWriter. In the case of the Loader Framework these classes have been written for you. They are the LexGrid model objects that use Hibernate to write to the database. Key DirectoriesBelow is an image of the loader-framework-core project in Eclipse which shows the key directories of the Loader Framework. The following is a summary of the contents of those directories.
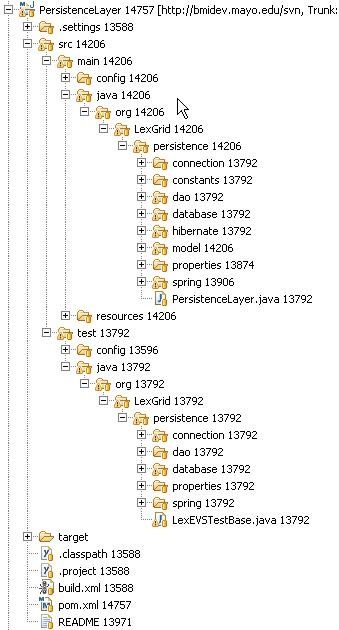
AlgorithmsNone Batch ProcessesNone Error HandlingSpring Batch gives the Loader Framework some degree of recovery from errors. Like the other features of Spring it is something the Loader developer would need to configure in their Spring config file. Basically, Spring will keep track of the steps it has executed and make note of any step that has failed. Those failed steps can be re-run at a later time. The Spring documentation provides additional information on this function. See http://static.springsource.org/spring-batch/reference/html/configureJob.html and http://static.springsource.org/spring-batch/reference/html/configureStep.html. Database ChangesNone ClientCurrently, the LexBIG GUI does not provide a framework to dynamically load extendable GUI components. While not impossible to extend the GUI functionality especially for those working closely with the LexBIG code, loaders written to use the new framework should expect that their loader will be called via the command line or script. JSP/HTMLNone ServletNone Security IssuesNone. PerformanceSpring can accommodate parallel processing to enhance performance. The Spring documentation provides a good discussion of this topic. See http://static.springsource.org/spring-batch/reference/html/scalability.html. InternationalizationNot Internationalized Installation / PackagingThe Loader Framework is packaged as a LexBIG extension and thus is not included in the LexBIG jar. MigrationNone. Documentation ConsiderationsThe Loader Framework will also be described in the knowledge center. TestingAutomated test are run via Maven. As mentioned earlier the projects containing the Loader Framework code are configured to work with Maven. Figure 6 (below), shows how the PersistenceLayer project and its standard Maven layout. Notice the structure of the test code mirrors the structure of the application code. To run the automated test in our Eclipse environment we select the project, right click, select 'Run As' and select 'Maven test'. Maven will do the rest.
Test GuidelinesThe test cases are also integrated into the LexBIG 5.1 build environment and are run with each build. Test CasesSee System Testing. Test ResultsSee System Testing. Feasibility Report and RecommendationPersistence Layer Feasibility The Persistence Layer enables LexEVS to have a single access point to the underlying database. This has several advantages:
As LexEVS moves forward, the Persistence Layer is also flexible enough to play a part in the runtime Query API. With this, the runtime and loader code would be able to share a common Data Access Layer - we would then have a true DAO Layer. Loader Framework Feasibilty The Loader Framework has been implemented for two loaders, the UMLS single ontology loader and the NCI Metathesaurus loader. These loaders that implement the Loader Framework simple must define the READ and TRANSFORMATION mechanisms for the load, as well as load order and flow. All common details of Loading to LexEVS will be dealt with by the Loader Framework and will not have to be implemented. Tools exist for:
Also, to aid in Transformation, basic building blocks have been created that users may extend, such as:
Several Utilities are also available for Reading and Writing, such as:
Implementation PlanThis will include the technical environment (HW,OS, Middleware), external dependencies, teams/locations performing development and procedures for development (e.g. lifecycle model,CM), and a detailed schedule. Technical environmentNo new environment requirements exist for the the LexEVS 5.1, with the exception of additional storage to accommodate larger content loads. Software (Technology Stack)Operating System
Application Server
Database Server
Other Software Components
Server HardwareServer
Minimum Processor Speed
Minimum Memory
StorageExpected file server disk storage (in MB)
Expected database storage (in MB)
NetworkingApplication specific port assignments
JBoss Container Considerations There are specific requirements for JBoss containers for LexEVS 5.1. In order to support multiple versions of LexEVS (for example 5.0 and 5.1), there are JBoss considerations.
External dependenciesN/A Team/Location performing development
Procedures for DevelopmentDevelopment will follow procedures as defined by NCI. Detailed scheduleThe LexEVS 5.1 project plan is located in Gforge at: LexEVS 5.1 Project Plan and LexEVS 5.1 Project Plan (PDF) The LexEVS 5.1 BDA Project plan is located at: LexEVS 5.1 BDA Project Plan Training and documentation requirementsN/A Download center changesN/A |