Page History
| Scrollbar | ||
|---|---|---|
|
...
| Panel | ||
|---|---|---|
| ||
Author: Craig Stancl, Scott Bauer, Cory Endle |
...
The focus is on the functionalities proposed by the stakeholders and target users to make a better product.
Design Scope and Requirements
The LexEVS 6.4 Scope Document can be found here: LexEVS 6.4 Scope Document
Requirements
The LexEVS 6.4 Requirements Document can be found here: LexEVS 6.4 Requirements Definition Document
Detailed Design
The following sections specify how the design will satisfy the requirements for the Lucene search upgrade. This design reflects the wide ranging changes that will be necessary to LexEVS to fully update over three full releases of Lucene. Since Lucene is the heart of the search mechanism that powers efficient searches in LexEVS these changes are necessarily extensive. The focus of these changes can be broken down, to some extent, into three areas.
- Code decoupling from the current Lucene to allow for easier updates to the underlying search implementation.
- Multi-index searches to replace single index searches. This will allow easier maintenance than the large, monolithic index we currently use.
- Using the built in relational index structures of the latest Lucene release to replace the hand built version of this in the current LexEVS implementation.
- Code refactoring to the latest Lucene code base. This requires extensive changes to the code base including replacement of objects with similar behavior for the current code base and adjusting to changes in the Lucene API. This also includes reimplementing a number of customized Lucene analysers analyzers and HitCollectors to insure compatibility with current code unit tests and user expectations.
Some classes are called out to indicate the extent of the changes and to document some of the details of intended adjustments.
Code Decoupling
Multi-Index Searches
The Current Implementation
Our current search for coding schemes within a monolithic index requires use of a Lucene Filter dependent on an XML file called metadata.xml. This file has a handmade concurrency protecting class providing access and relies on the processing of DOM objects in order to provide both filtering of more granular entities in the system, and listings of the code systems in general. As such it is something of a bottleneck for access.
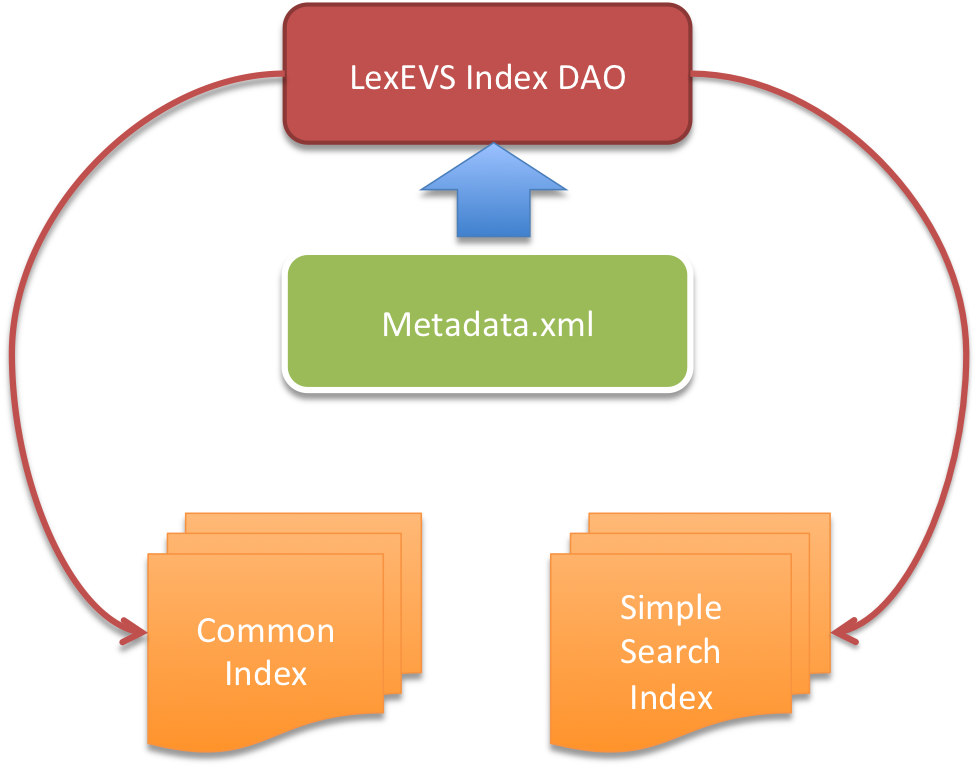
A Proposed, Revised Metadata Implementation
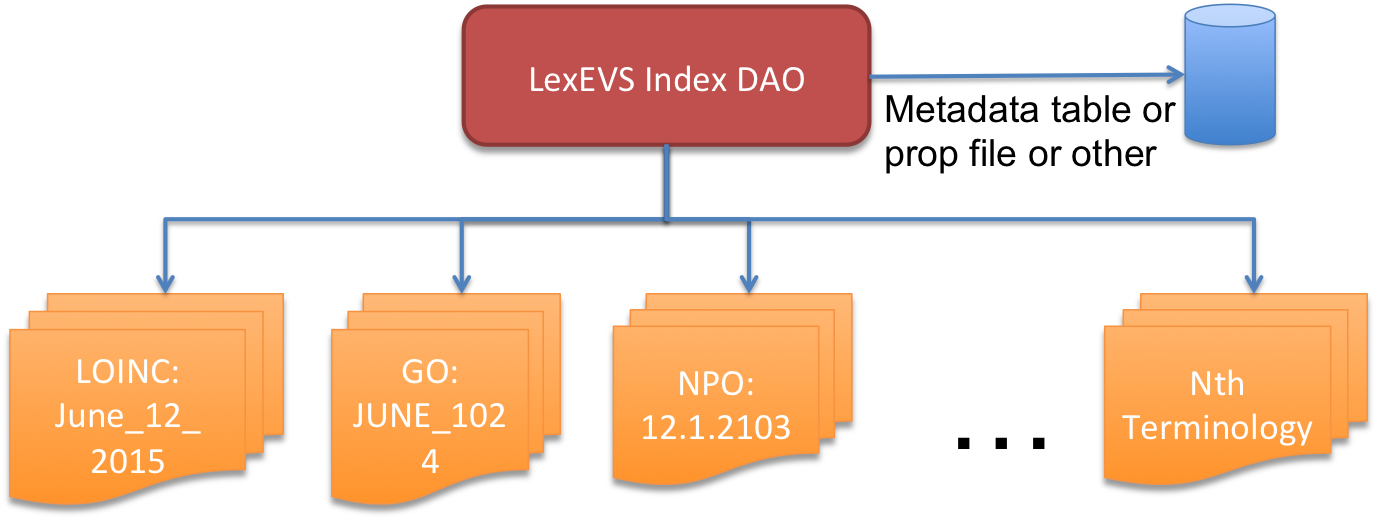
With the advent of an index per code system design. The metadata structure can go away. In it's place a contextual file read of the names of the indexes with additional metadata persistence where necessary will replace the concurrent xml parsing.
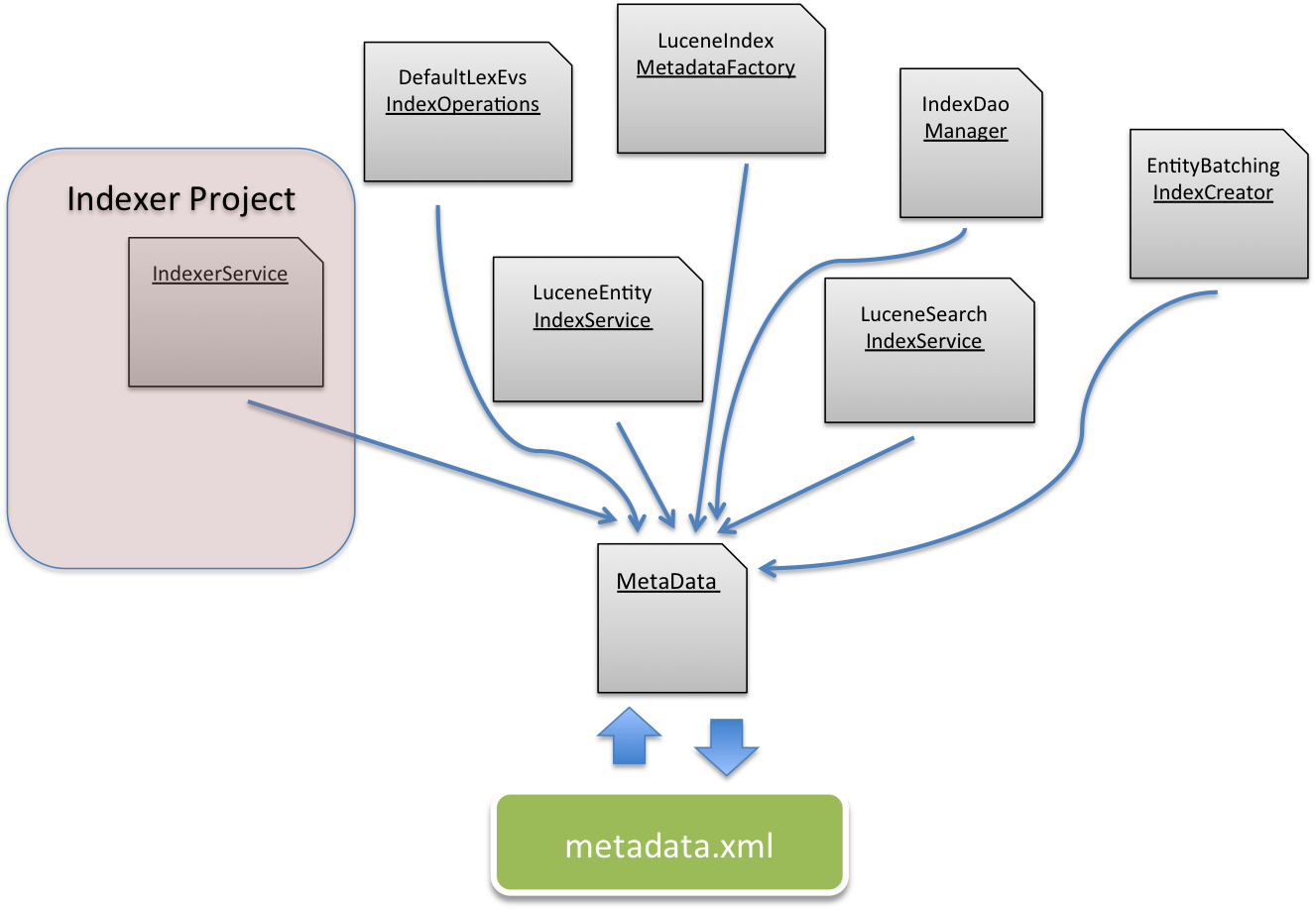
MetaData Dependencies
The many dependencies on the metadata.xml file and it's accompanying MetaData class will have to be refactored to a new implementation. All classes in the Indexer will be dropped or pulled into the dao project
The many dependencies on the metadata.xml file and it's accompanying MetaData class will have to be refactored to a new implementation. All classes in the Indexer will be dropped or pulled into the dao project
Changing MetaData Dependency Class Call Outs
| Code Block | ||||
|---|---|---|---|---|
| ||||
//Not really an interface, as a class it will need to be rethought, reimplemented to accommodate multi-index initialization.
org.lexevs.dao.index.connection.IndexInterface
//This class attempts to manage index events concurrently and is highly dependent on the parsing of an XML file
edu.mayo.informatics.indexer.utility.MetaData
//Along with the above a multi index implementation of this interface will have to be done.
//The pertinent implementation of this provides an in memory collection of objects consistent with the metadata elements
//Registration consists of updating this collection in conjunction with the metadata file.
org.lexevs.dao.index.indexregistry.IndexRegistry
//A good portion of the metadata file is created in this extension of the IndexCreator.
//Since the metadata.xml is going away — we’ll want to reimplement
org.lexevs.dao.index.indexer.EntityBatchingIndexCreator
//Creates and deletes indexes. Managers readers and writers. Adds and deletes at the document level.
//Gets searchers. This lives in the Indexer, if it’s on the code path it needs to be updated,
//otherwise it should be tossed out.
edu.mayo.informatics.indexer.api.IndexerService
// This and its interface EntityIndexService may or should replace the IndexerService. Needs closer examination.
org.lexevs.dao.index.service.entity.LuceneEntityIndexService
//Central manager for Search, Metadata, and Common indexes as well as the metadata.xml managing class
//Since this class uses some of the properties recorded for the index we will need to see what depends on these values
//and how they can be otherwise provided.
org.lexevs.dao.index.access.IndexDaoManager
//Index CRUD service. Cleanup methods serve to do some updates.
//Depends on Dao, MetaData and Registry classes and contains some Lucene objects
org.lexevs.dao.index.operation.DefaultLexEvsIndexOperations
// Spring wired factory class that implements Spring FactoryBean to create singleton MetaData class
org.lexevs.dao.index.lucenesupport.LuceneIndexMetadataFactory
//Works largely at the entity level of creation and deletion but also can drop full indexes,
//as well as create them and query indexes it has created.
org.lexevs.dao.index.service.search.LuceneSearchIndexService |
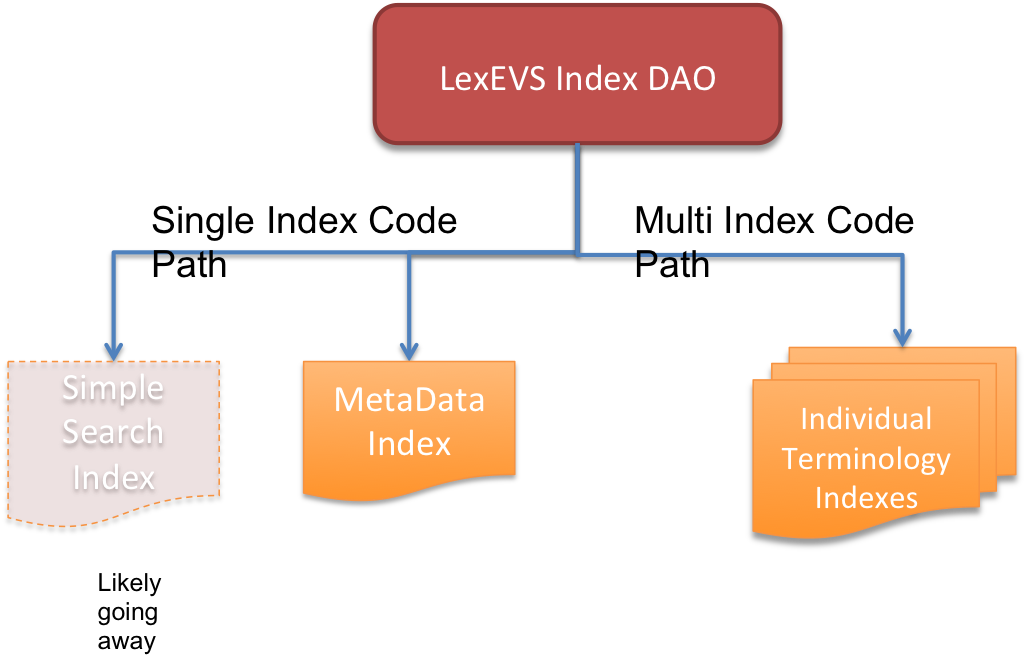
Code Path Maintenance and Additions
Some support for the remaining MetaData index will have to remain. An effort will be made to leverage remnants of old multi-index implementations. In essence we'll be maintaining two code paths for this purpose.
| Code Block | ||||
|---|---|---|---|---|
| ||||
//This Index “template” interface directly calls Lucene reader/write elements. It’s base and multi base implementations will need to be adjusted
//to some extent, but it’s clear that some support still exists for multiple index reading writing. Some of both will have to be maintained for the
//remaining MetaData index search (different from the metadata.xml) and possibly the simple search.
org.lexevs.dao.index.lucenesupport.LuceneIndexTemplate |
Changing the Relational Representation in Lucene
General Code Refactoring
...
LexEVS Multi-index Lucene Implementation
Changing the Relational Representation in Lucene
LexEVS Lucene Relational Representation
Per-segment Search
LexEVS Per-segment Search Implementation
Hit Collector to Collector Updates
| Add Page | ||||||
|---|---|---|---|---|---|---|
|
Analyzer Updates
| Add Page | ||||||
|---|---|---|---|---|---|---|
|
Index Code Refactor: Removing the Indexer Project
| Add Page | ||||||
|---|---|---|---|---|---|---|
|
Audit of Text Matching Use Cases
| Add Page | ||||
|---|---|---|---|---|
|
Consideration of Build Impacts
| Add Page | ||||
|---|---|---|---|---|
|
Index Compatibility with Previous Index Versions
This update will be to Lucene 5.0. This version of Lucene has some backwards compatibility with Lucene 4.0 indexes. However it is completely incompatible with indexes versions 3.x and earlier. While LexEVS API's will maintain backwards compatibilities, any indexes from previous installed will have to be re-indexed in the latest implementation.
Pagination in Lucene
Lazy loading pagination is a broad concept in LexEVS and can encompass both graph and node set capabilities. Because this scope is large we are going to consider this out of scope for this project unless we can define a fairly narrow definition of what we want to do with Lucene's version of this. Currently some lazy loading occurs under the covers in the iterators returned by the coded node set implementation. We also have node graph pagination. In either case we may not need a reimplementation in order to update our Lucene implementation. We are suggesting this become a possible priority for a later implementation and won't fully describe how this might be done here.
Impacts to Existing Users / Applications
Minimal impact overall expected with increased performance and maintenance efficiency expected.
| Impact Description | Reference to documented impact |
|---|---|
| Text Matching Algorithm Changes. Support for a wide ranging text matching capability creates potential for heavy maintenance. We have attempted to characterize the similarities between some term matching implementations with an eye towards exclusion or combination. This exclusion and combination only affects end users if we remove labels as algorithm switches. | Not specifically impact documentation but a background document: LexEVS Text Match Algorithm Audit |
| Index File System Changes. Index files will exist per coding scheme. This creates the opportunity for unmerged terminology indexes that should improve maintenance efficiency through quicker load times and the ability to identify and remove broken indexes without having to reindex the entire service. This will change the appearance of the file system but should not cause any issues for end users. The API will remain the same. | Background: |
| Faster Query Performance on at Least Some Queries. The goal is to at least make queries no slower than current queries. The use of Block Join Queries has a reputation for being faster. This implementation has some opportunity to provide small indexes if we can properly capitalize during implementation. | Background: |
| Index Optimization Function Will Go Away. Index optimization no longer serves the purpose originally intended in Lucene. The optimization function should be deprecated and the implementation changed to output a message that indexes no longer need optimizing. |
Decision Points - Approval Needed
Pagination in Lucene - DEFERRED
Reference: LexEVS 6.4 Software Design Document
Sign off | Date | Role | CBIIT or Stakeholder Organization | Approver's Comments (If disapproved indicate specific areas for improvement.) |
|---|---|---|---|---|
| Larry Wright | 4/24/2015 | Govt Project Manager | CBIIT EVS | --- |
Sherri de Coronado | 4/30/2015 | Govt Sponsor | CBIIT EVS | — |
Kumar Kuntipuram | 4/30/2015 | TPM | Leidos Biomed | — |
Reduction of Text Matching Algorithms
Reference: LexEVS Text Match Algorithm Audit
Text Matching Algorithms to be continued: This list to be provided when the development team begins to work on these algorithms.
- Consideration needs to be given to "Contains" search as it doesn't currently behave correctly. (JIRA LEXEVS-XX)
Sign off | Date | Role | CBIIT or Stakeholder Organization | Approver's Comments (If disapproved indicate specific areas for improvement.) |
|---|---|---|---|---|
| Larry Wright | 4/24/2015 | Govt Project Manager | CBIIT EVS | --- |
Sherri de Coronado | 4/30/2015 | Govt Sponsor | CBIIT EVS | — |
Kumar Kuntipuram | 4/30/2015 | TPM | Leidos Biomed | — |
Lucene Code Decoupling - DEFERRED
Reference: LexEVS Code Decoupling
Sign off | Date | Role | CBIIT or Stakeholder Organization | Approver's Comments (If disapproved indicate specific areas for improvement.) |
|---|---|---|---|---|
| Larry Wright | 4/24/2015 | Govt Project Manager | CBIIT EVS | --- |
Sherri de Coronado | 4/30/2015 | Govt Sponsor | CBIIT EVS | — |
Kumar Kuntipuran | 4/30/2015 | TPM | Leidos Biomed | — |
Relevant JIRA Items
Detailed Design - Provide the architecture and design for the new Lucene feature.
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
The following JIRA items are all part of LEXEVS-724.
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
...
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
| Jira | ||||||||
|---|---|---|---|---|---|---|---|---|
|
...
...