Overview
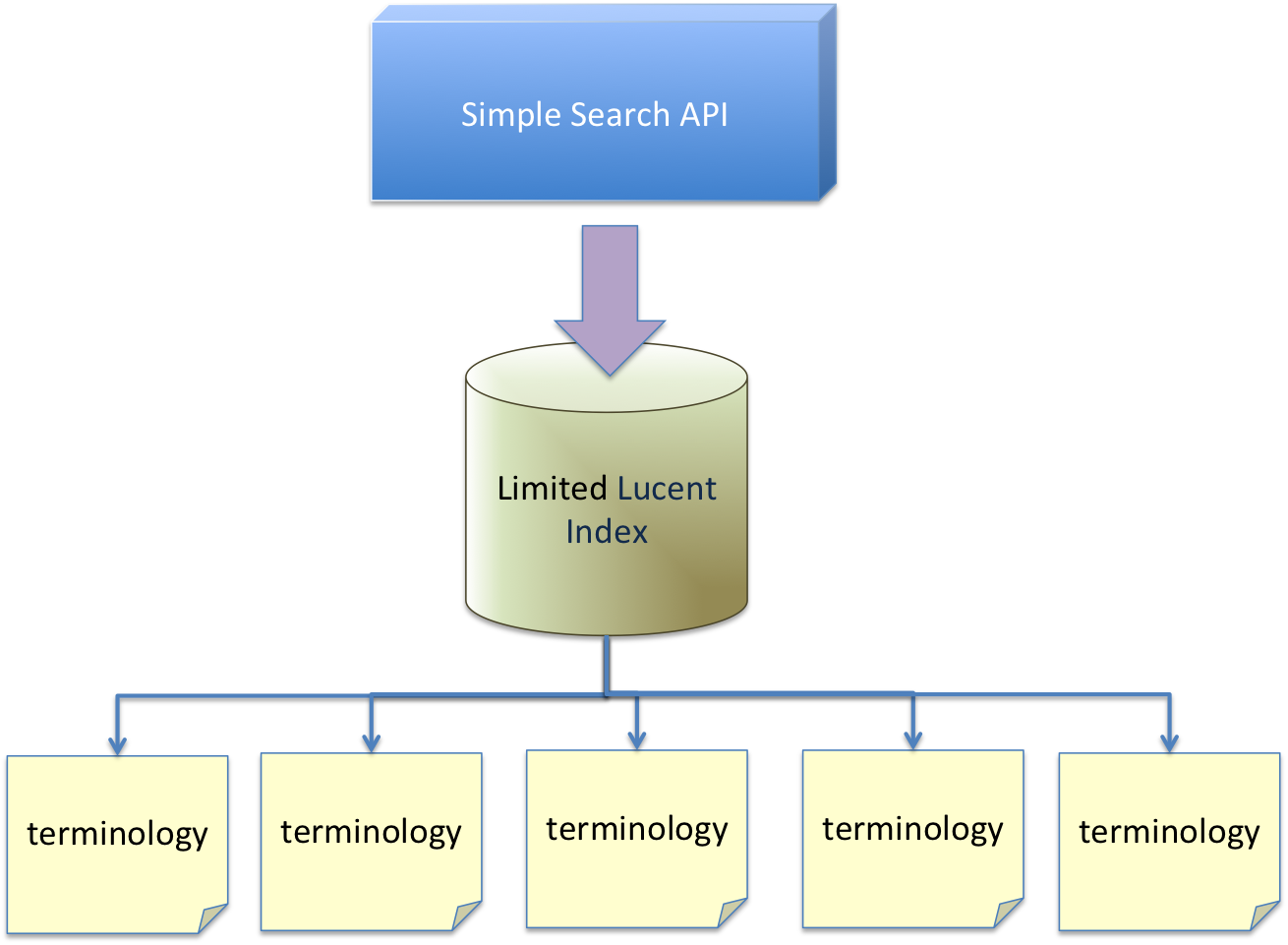
Search mechanisms using Lucene can become overburdened as increasing numbers of use cases make for a larger and more complex Lucene index. When a use case as comprehensive as searching a terminology service for a term, or fragment, is proposed then a more restricted manner of approaching the problem is in order. Furthermore the use of the power of the LexEVS API becomes overkill, with the necessity of the union of large datasets prior to the effective query, Subsequently, a more restricted approach is necessary.
A Simplified Search API
The model for Entity in LexEVS/LexGrid is robust and complete enough that it allows extensive metadata and properties to be compounded within the entity's scope when loaded from an extensively defined source into the LexGrid data model. However, the lexical, or human readable aspects of this model element are relatively restricted and among those aspects that are human readable few need to be searched in order to return results that fit into the majority of use cases. Reducing the matching algorithms available to a text match in these circumstances can also allow relatively good performance over a larger data set in Lucene. The proposition here is to use a "contains" match algorithm only.
A Higher Performance Lucene
Multi Terminology Searches