Pick List Definition
An ordered list of entity codes and corresponding presentations drawn from a resolved value set definition.
Pick List Definition logical model
Here is a UML representation of Pick List Definition with in LexGrid 201001 model:
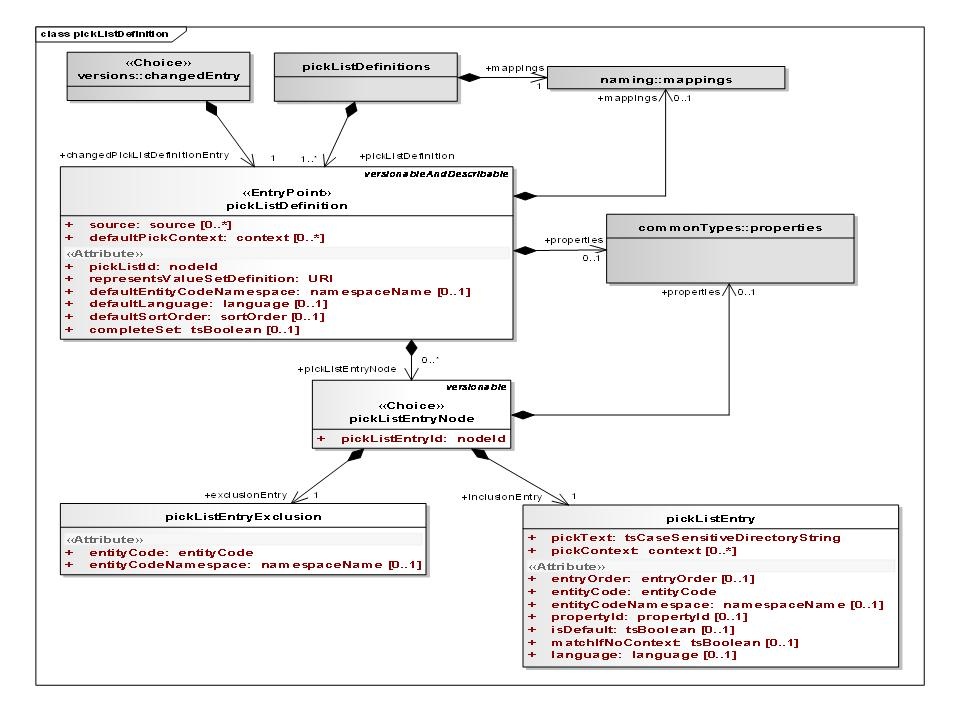
Pick List Definition logical Model Description
Pick List Definition
An ordered list of entity codes and corresponding presentations drawn from a resolved value set definition.
Attributes of Pick List Definition
The following is a list of attributes of the pick list definition.
- Source: The local identifiers of the source(s) of this pick list definition. Must match a local id of a supportedSource in the corresponding mappings section.
- pickListId: An identifier that uniquely names this list within the context of the collection.
- representsValueSetDefinition: The URI of the value set definition that is represented by this pick list
- defaultEntityCodeNamespace: Local name of the namespace to which the entry codes in this list belong. defaultEntityCodeNamespace must match a local id of a supportedNamespace in the mappings section.
- defaultLanguage: The local identifier of the language that is used to generate the text of this pick list if not otherwise specified. Note that this language does NOT necessarily have any coorelation with the language of a pickListEntry itself or the language of the target user. defaultLanguage must match a local id of a supportedLanguage in the mappings section.
- defaultSortOrder: The local identifier of a sort order that is used as the default in the definition of the pick list
- defaultPickContext: The local identifiers of the context used in the definition of the pick list.
- completeSet: True means that this pick list should represent all of the entries in the resolved value set definition. Any active entity codes that aren't in the specific pick list entries are added to the end, using the designations identified by the defaultLanguage, defaultSortOrder and defaultPickContext. Default: false
Pick List Entry Node
An inclusion (pickListEntry) or exclusion (pickListEntryExclusion) in a pick list definition
Attributes of Pick List Entry Node
pickListEntryId: Unique identifier of this node within the list.
Pick List Entry
An entity code and corresponding textual representation.
Attributes of Pick List Entry
The following are attributes of the pick list entry.
- pickText: The text that represents this node in the pick list. Some business rules may require that this string match a presentation associated with the entityCode
- pickContext: The local identifiers of the context(s) in which this entry applies. pickContext must match a local id of a supportedContext in the mappings section
- entryOrder: Relative order of this entry in the list. pickListEntries without a supplied order follow the all entries with an order, and the order is not defined.
- entityCode: Entity code associated with this entry.
- entityCodeNamespace: Local identifier of the namespace of the entity code if different than the pickListDefinition defaultEntityCodeNamespace. entityCodeNamespace must match a local id of a supportedNamespace in the mappings section.
- propertyId: The property identifier associated with the entityCode and entityCodeNamespace that the pickText was derived from. If absent, the pick text can be anything. Some terminologies may have business rules requiring this attribute to be present.
- isDefault: True means that this is the default entry for the supplied language and context.
- matchIfNoContext: True means that this entry can be used if no contexts are supplied, even though pickContext ispresent.
- Language: The local name of the language to be used when the application/user supplies a selection language matches. If absent, this matches all languages. language must match a local id od of a supportedLanguage in the mappings section.
Pick List Entry Exclusion
An entity code that is explicitly excluded from a pick list.
Attributes of Pick List Entry Exclusion
The following are attributes of the pick list entry exclusion.
- entityCode: Entity code associated with this entry.
- entityCodeNamespace: Local identifier of the namespace of the entity code if different than the pickListDefinition defaultEntityCodeNamespace. entityCodeNamespace must match a local id of a supportedNamespace in the mappings section.
Possible forms of Pick List Definitions
The following are possible forms of the pick list definitions.
- Ability to include all the concept codes contained in the referenced value set resolution by setting completeSet flag to 'true'
- Ability to include individual pickText derived from concept code designation of the referenced code system
- Ability to exclude concept codes from the pick list
- Ability to combine of any of the above
Examples of Pick List Definitions
Example 1
So we have a Code System "Automobiles" that contains concept codes, and we also have a Value Set Definition 'urn:BDExample1' that contains all the concept root code '@' from this code system.
To define the definition to include all the preferred designations from the concept codes that are contained in Resolved Value Set Definition 'urn:VDExample1,' we could define it as
pickListDefinition pickListid : PLexample1 representsValueSetDefinition : urn:Vexample1 completeSet : true
And when this definition is resolved, we will get back all the preferred designations.
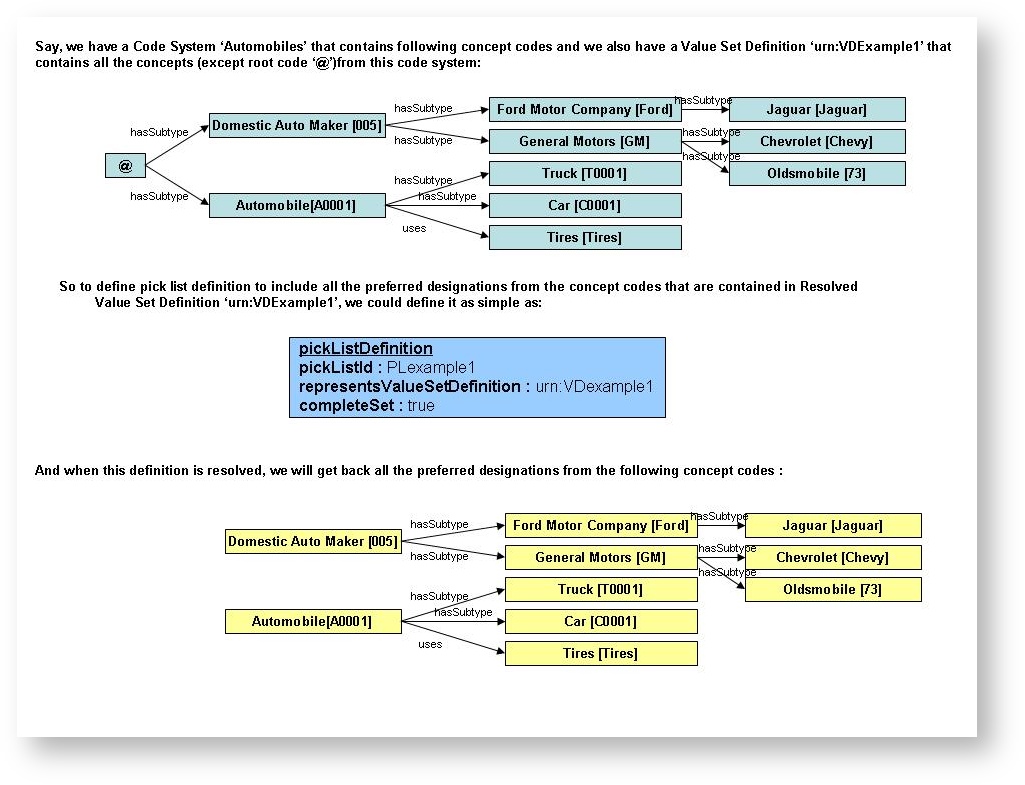
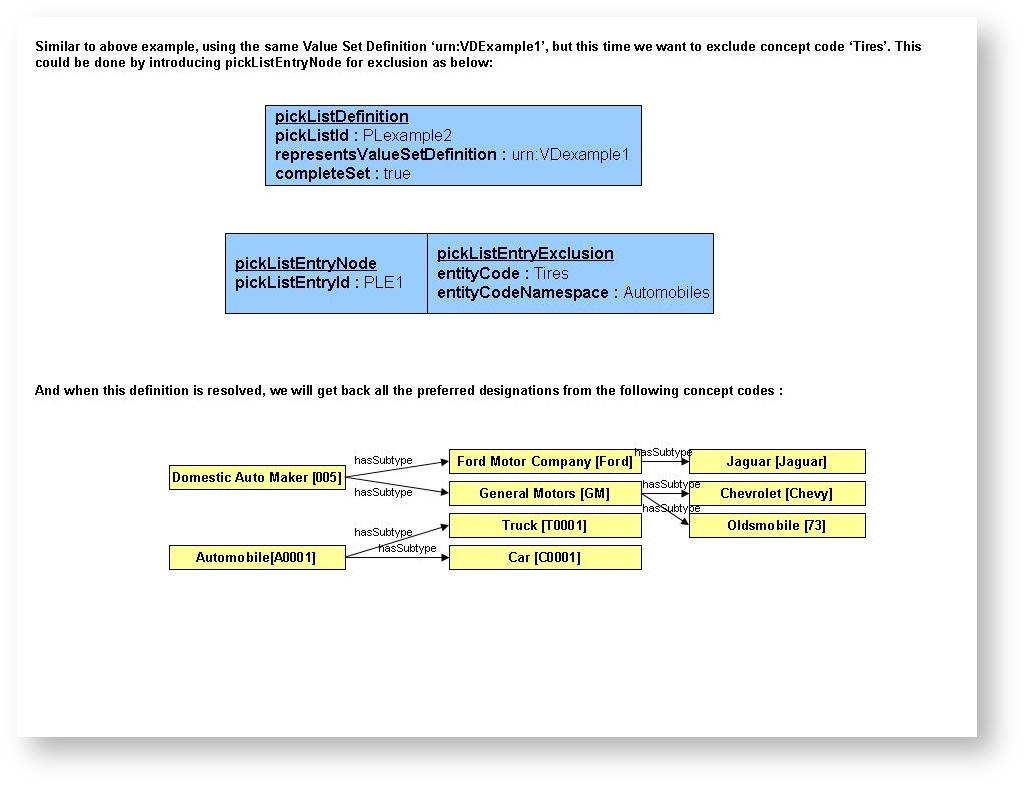
Example 2
Similar to the above example, using the same Value Set Definition 'urn:BDExample1,' but this time we want to exclude concept code 'Tires.' This could be done by introducing picListEntryNode for exclusion. When the definition is resolved, we will get all the preferred designations from concept codes.
Pick List Definition Versions
Pick List Definitions are versioned. The version of Pick List Definition changes when ever the definition is changed, it could be changing, adding or removing pickListEntryNode.
Pick List Services
Visit LexEVS 6.x Pick List Service for detailed Pick List Definition Services documentation.
Value Set/Pick List GUI
Visit LexEVS 6.x Value Set GUI for detailed functionality and howto's about using Value Sets developer GUI tool