Author: Craig Stancl, Scott Bauer, Cory Endle
Email: Stancl.craig@mayo.edu, bauer.scott@mayo.edu, endle.cory@mayo.edu
Team: LexEVS
Contract: S13-500 MOD4
Client: NCI CBIIT
National Institutes of Heath
US Department of Health and Human Services
Lucene Analyzers in LexEVS
Analyzer implementation under Lucene 5.0 is perhaps the most critical activity in the entire project. Getting them right ensures that the LexEVS API continues to return values in the same way it previously did. The analyzers are largely implemented per field, meaning there is a wrapper around several analyzers, each of which provides functionality towards tokenizing individual fields in one manner or another. Some of these analyzers might be able to be replaced with corresponding implementations from the Lucene libraries, but others are highly customized and make use of specially curated character escaping sets and special treatment for certain characters. Any changes in the way these work should be fully vetted with stakeholders. In general the entire set of text matching strategies should be audited for use and potential exclusion for purposes maintainability. This may result in a reduced dependency on custom analytics that serve a narrow purpose and requires more attention than off the shelf components.
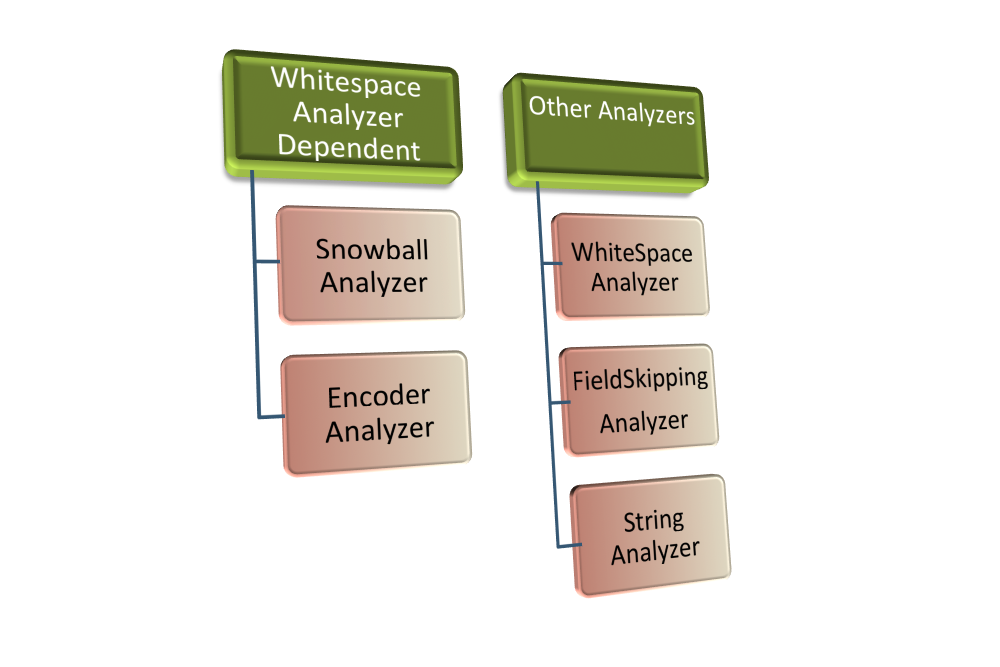
Current Analyzer Classes
//Wraps the other Analyzers. This is a Lucene class and it's implementation has been updated to //add analyzers during initialization (In the constructor). This will need to be adjusted in our //use of it. org.apache.lucene.analysis.PerFieldAnalyzerWrapper //This analyzer is an implementation of a similar class in Lucene. Presumably we are using //custom lists of characters to escape or otherwise treat as white space. A number of other //custom analyzers rely on this class for a token stream. It's central to the implementaion. edu.mayo.informatics.indexer.lucene.analyzers.WhiteSpaceLowerCaseAnalyzer //This would be a good candidate for replacement by a standard Lucene analyzer, but it is fed //a token stream by the WhiteSpaceLowerCaseAnalyzer before it does it's processing so we'll make //the necessary adaptations edu.mayo.informatics.indexer.lucene.analyzers.SnowballAnalyzer //Appears to be a fully custom analyzer that acts as a utility for other analyzers. //Not sure if we ever encode with it, but it is initialized //at query time. It may be a candidate for removal. edu.mayo.informatics.indexer.lucene.analyzers.FieldSkippingAnalyzer //Not dependent on WhiteSpaceLowerCaseAnalyzer. //Wraps a Lucene KeywordAnalyzer class. edu.mayo.informatics.indexer.lucene.analyzers.StringAnalyzer //Encodes for DoubleMetaphone. Would replace with Lucene implementation of a Double Metaphone Analyzer //if possible but this is also fed a WhiteSpaceLowerCaseAnalyzer token stream for processing edu.mayo.informatics.indexer.lucene.analyzers.EncoderAnalyzer //This normalizing analyzer appears to be disabled in the LuceneLoaderCode class. //We should remove it from the code path if it is not being used. edu.mayo.informatics.indexer.lucene.analyzers.NormAnalyzer