Entities and their Properties
Entities in LexEVS are conceived of as a unifying node with a set of properties that are related to it.

LexEVS Entities typically have a unique identifier (entityCode) and a set of values that provide some help in supporting the entities definition within a coding scheme. A set of properties, which can be of a given type, are associated with this unifying node.

This concept of an Entity with its properties is well represented and easily queried in a relational database:

However Lucene's indexing system was not designed for queries that allowed some sense of containment of properties by an entity. Its relational aspect groups values together in parent/child groups, but no query support exists for creating relational style queries. Instead queries are on discrete "Documents" and are largely based on boolean like queries.
In this case a query that stated it wanted an entity with both Property: heart and Property: cardiac would return nothing. No document has both cardiac and heart as properties. However if the query is made for Property: heart or Property: cardiac then any document set that contained cardiac or heart would be returned. This means that a property grouped with another entity would be returned and the results would be less accurate.
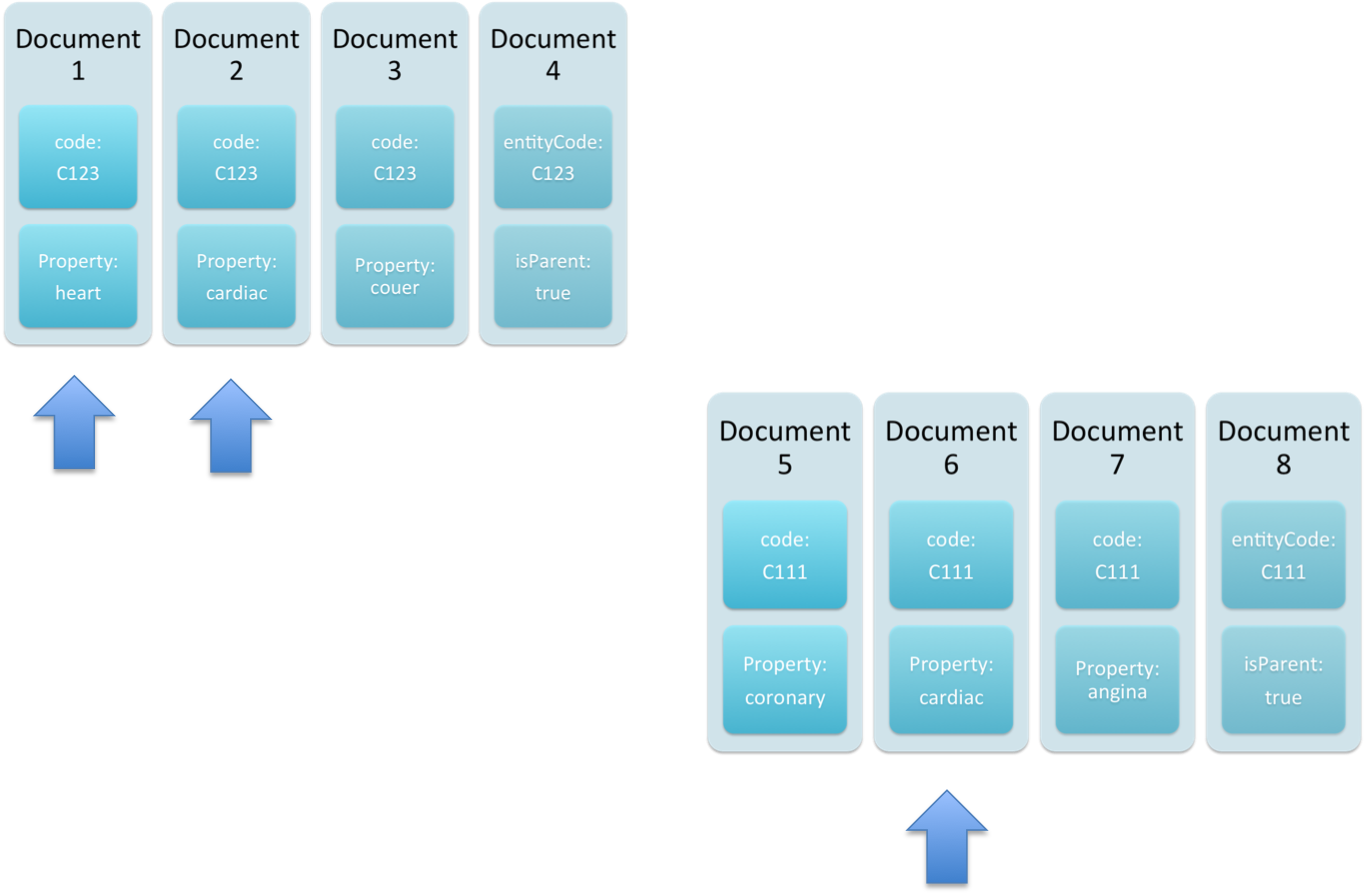
Previous implementations of Lucene in LexEVS used a complex method of queries to mark successful queries and group together those results that matched the property values that should occur together within a single entity. These methods are obsolete in the latest Lucene and will have to be reimplemented in some form.
Simplifying Operations Management While Implementing Entity Centered Query Calls
Entity centered querying can work when Lucene users query the index with a query that must return an answer based on two separate queries that will return a single entity value when both query values exist in that entity. This can be accomplished when queries are separately made block join queries returning the parent which are subsequently joined as queries that must return found values. This would effectively return an entity which was queried for two separate property values both of which existed in that entity.
This is the current state of the sequence of calls to get an entity using calls to the coded node set with at least one restriction:

An update to Lucene 5.3.1 will coincide with a simplification of this set of method calls as follows:

PlantUML definition documents:
Conclusion and Caveats
These diagrams show the code is simplified and we know from the Unit tests that the treatment of parent/children constructions as whole entities works under these circumstances. This has the side effect of of changing result listing in searches against multiple coding schemes. Current testing is based on a listing of values which is sometimes boosted to achieve a set of values returned in an order expected based on the boost value. Custom scoring techniques that somehow get tests to pass may be fragile and relatively meaningless. For any set of terminologies a query into a terminology is scored based on the context of that terminology. If a set of scores is collected from a group of terminologies, the compiled scores do not have any real relationship to one another. Depending on the original scores boosting these scores may or may not result in higher position placement with a list. This boosting may return a more ordered list from an index compiled from an arbitrarily grouped set of terminologies in a single index, however there is no guarantee that that the scoring will have more meaning without some kind of coordinated curation of the grouping of terminologies.