Author: Craig Stancl, Scott Bauer, Cory Endle
Email: Stancl.craig@mayo.edu, bauer.scott@mayo.edu, endle.cory@mayo.edu
Team: LexEVS
Contract: S13-500 MOD4
Client: NCI CBIIT
National Institutes of Heath
US Department of Health and Human Services
Multi-Index Searches
The Current Implementation
Our current search for coding schemes within a monolithic index requires use of a Lucene Filter dependent on an XML file called metadata.xml. This file has a handmade concurrency protecting class providing access and relies on the processing of DOM objects in order to provide both filtering of more granular entities in the system, and listings of the code systems in general. As such it is something of a bottleneck for access.
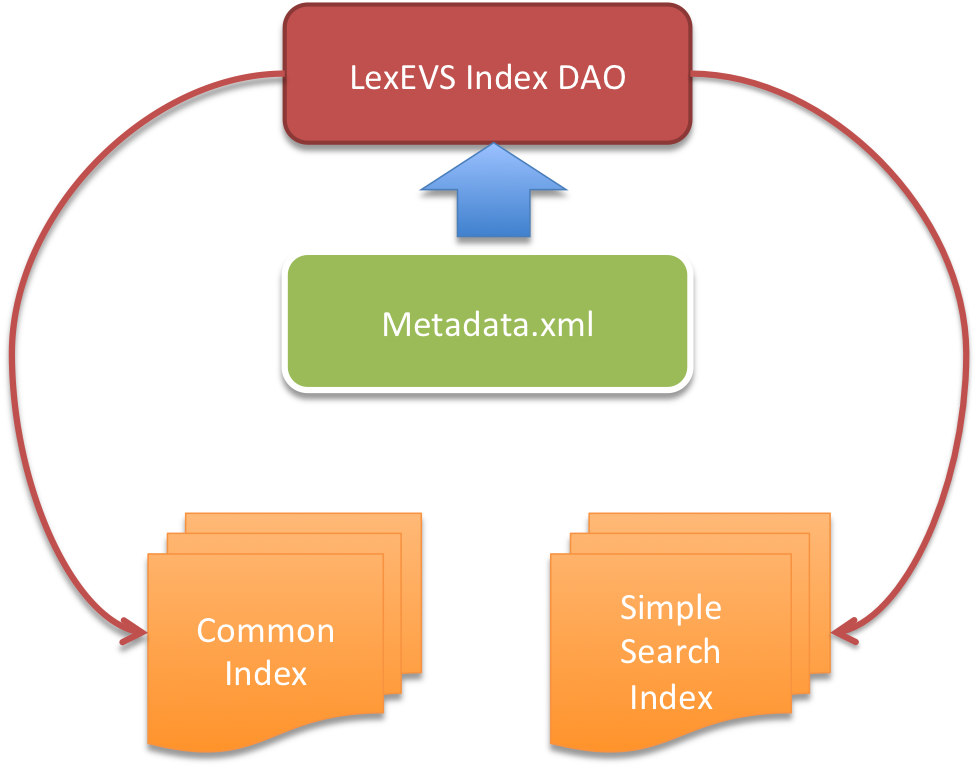
A Proposed, Revised Metadata Implementation
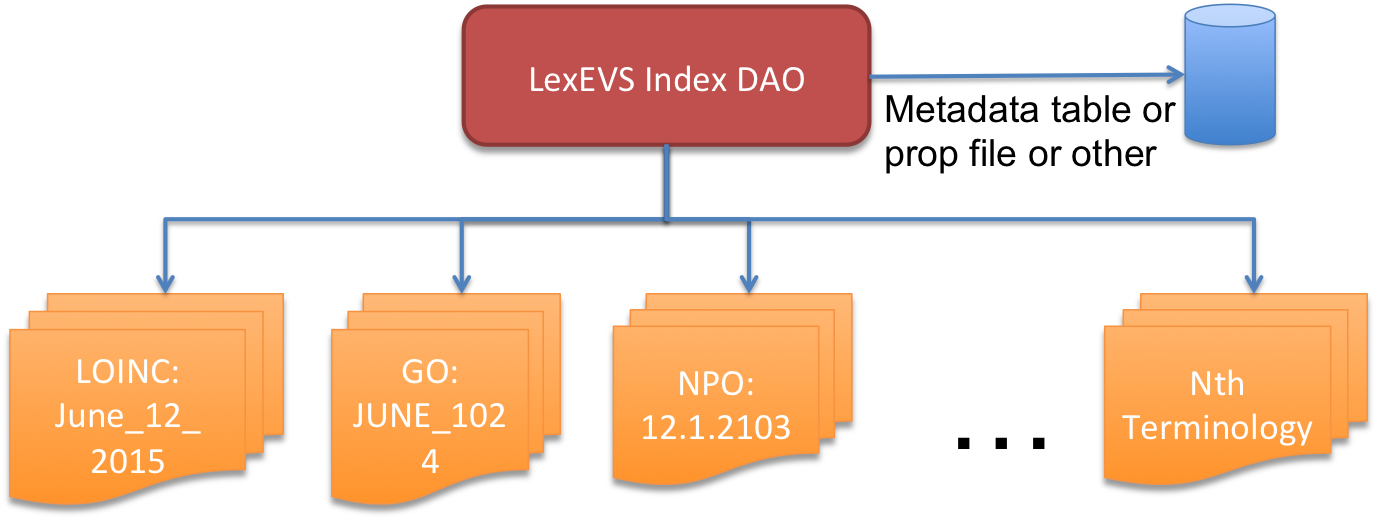
With the advent of an index per code system design. The metadata structure can go away. In it's place a contextual file read of the names of the indexes with additional metadata persistence where necessary will replace the concurrent xml parsing.
The many dependencies on the metadata.xml file and it's accompanying MetaData class will have to be refactored to a new implementation. All classes in the Indexer will be dropped or pulled into the dao project
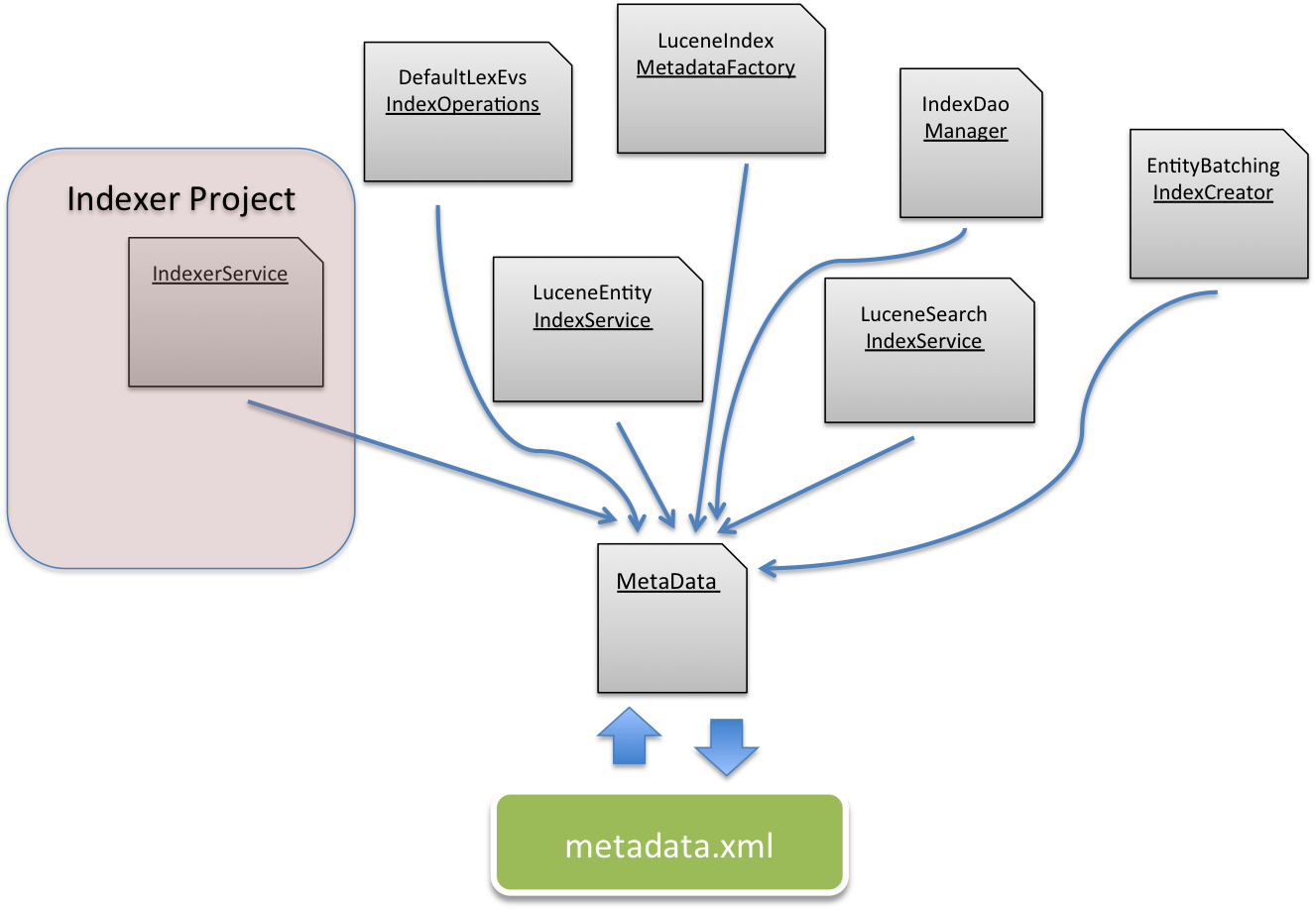
Changing MetaData Dependency Class Call Outs
//Not really an interface, as a class it will need to be rethought, reimplemented to accommodate multi-index initialization. org.lexevs.dao.index.connection.IndexInterface //This class attempts to manage index events concurrently and is highly dependent on the parsing of an XML file edu.mayo.informatics.indexer.utility.MetaData //Along with the above a multi-index implementation of this interface will have to be done. //The pertinent implementation of this provides an in memory collection of objects consistent with the metadata elements //Registration consists of updating this collection in conjunction with the metadata file. org.lexevs.dao.index.indexregistry.IndexRegistry //A good portion of the metadata file is created in this extension of the IndexCreator. //Since the metadata.xml is going away — we’ll want to reimplement org.lexevs.dao.index.indexer.EntityBatchingIndexCreator //Creates and deletes indexes. Managers readers and writers. Adds and deletes at the document level. //Gets searchers. This lives in the Indexer, if it’s on the code path it needs to be updated, //otherwise it should be tossed out. edu.mayo.informatics.indexer.api.IndexerService // This and its interface EntityIndexService may or should replace the IndexerService. Needs closer examination. org.lexevs.dao.index.service.entity.LuceneEntityIndexService //Central manager for Search, Metadata, and Common indexes as well as the metadata.xml managing class //Since this class uses some of the properties recorded for the index we will need to see what depends on these values //and how they can be otherwise provided. org.lexevs.dao.index.access.IndexDaoManager //Index CRUD service. Cleanup methods serve to do some updates. //Depends on Dao, MetaData and Registry classes and contains some Lucene objects org.lexevs.dao.index.operation.DefaultLexEvsIndexOperations // Spring wired factory class that implements Spring FactoryBean to create singleton MetaData class org.lexevs.dao.index.lucenesupport.LuceneIndexMetadataFactory //Works largely at the entity level of creation and deletion but also can drop full indexes, //as well as create them and query indexes it has created. org.lexevs.dao.index.service.search.LuceneSearchIndexService
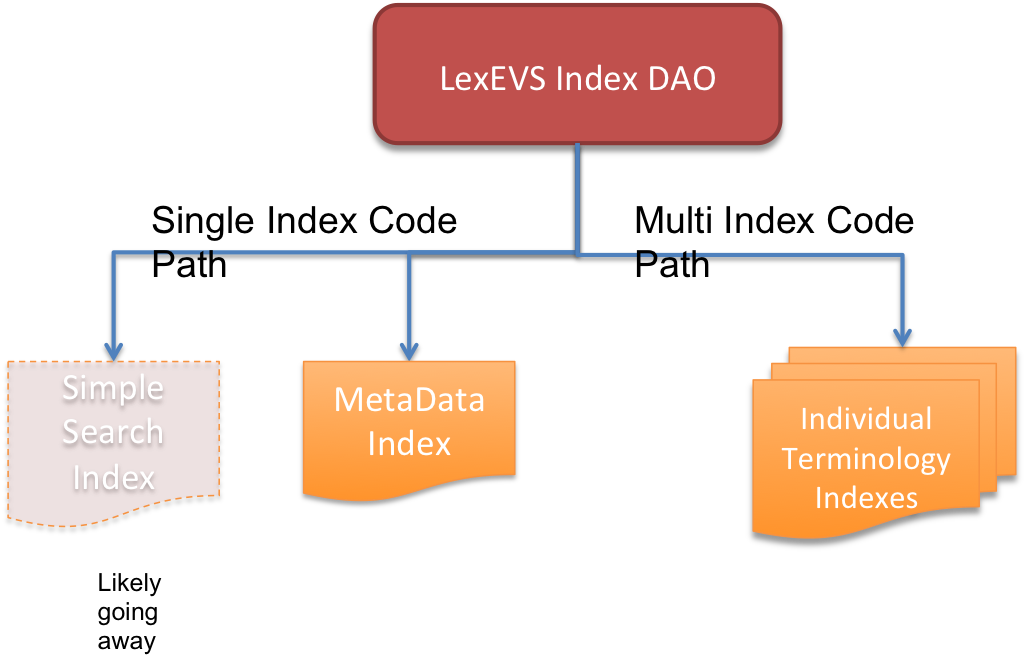
Code Path Maintenance and Additions
Some support for the remaining MetaData index will have to remain. An effort will be made to leverage remnants of old multi-index implementations. In essence we'll be maintaining two code paths for this purpose.
//This Index “template” interface directly calls Lucene reader/write elements. It’s base and multi-base implementations will need to be adjusted //to some extent, but it’s clear that some support still exists for multiple index reading/writing. Some of both will have to be maintained for the //remaining MetaData index search (different from the metadata.xml) and possibly the simple search. org.lexevs.dao.index.lucenesupport.LuceneIndexTemplate //The Dao layer will need a new start. Lucene 5.0 creates a clean break with previous Lucene formats. A format aware Dao for going forward //may provide some future proofing so we’ll continue to build on it, but at the same time break with the previous format support org.lexevs.dao.index.access.LexEvsIndexFormatVersionAwareDao org.lexevs.dao.index.access.AbstractBaseIndexDao org.lexevs.dao.index.lucene.AbstractFilteringLuceneIndexTemplateDao org.lexevs.dao.index.lucene.AbstractBaseLuceneIndexTemplateDao org.lexevs.dao.index.lucene.v2010.entity.LuceneEntityDao org.lexevs.dao.index.lucene.v2010.entity.SingleTemplateDisposableLuceneCommonEntityDao
Multiple Index Query Updates
While some code remains for this from a previous query structure, updates will be required to deal with deprecated Lucene class MultiSearcher. This is intended to be the replacement for the single index code paths and will have to be adapted and updated as needed
//This class inherits from the single index class we'll either merge code or leave the parent class in place org.lexevs.dao.index.lucenesupport.MultiBaseLuceneIndexTemplate //The parent class. Any per-segment search capabilities will need to be added as necessary org.lexevs.dao.index.lucenesupport.BaseLuceneIndexTemplate
Moving Towards an MMapDirectory Type
MMapDirectories offer an opportunity to take advantage of modern operating system memory management. In effect we set aside resources to insure that Lucene has enough memory available at all times. This is similar to what happens when you set up databases and other applications that need a minimum of resources in order to function properly. In essence we have a contract to get transparent memory resources as a virtual memory bank of RAM and Storage. Because we don't compete with other resources for this memory we are able to process indexing and search tasks more efficiently.
//These classes directly access the current Lucene directory object FSDirectory which will be updated to MMapDirectory org.lexevs.dao.index.lucenesupport.DefaultLuceneDirectoryCreator org.lexevs.dao.index.lucenesupport.LuceneDirectoryFactory.NamedDirectory //These classes also participate in the creation and deletion of a directory on a higher level in the code path org.lexevs.dao.index.lucenesupport.LuceneDirectoryFactory org.lexevs.dao.index.indexregistry.SingleIndexRegistry
Details of how Memory Mapping for Lucene works has been well documented here: