Page History
...
For the particular data in this example, the array data files are in the Agilent Raw TXT format. To specify this, in the 'Manage Files' window shown below, select 'Agilent Raw TXT' from the 'Select New File Type' drop-down list, then click on the 'Save' button above it. (NOTE: Depending on the assay type and array design used in your own experiment, your data may be in a different format, in which you will have to select the appropriate type that format from the drop-down list, or the file type may be automatically recognized by caArray, in which case you won't have to manually specify the file type it yourself.)
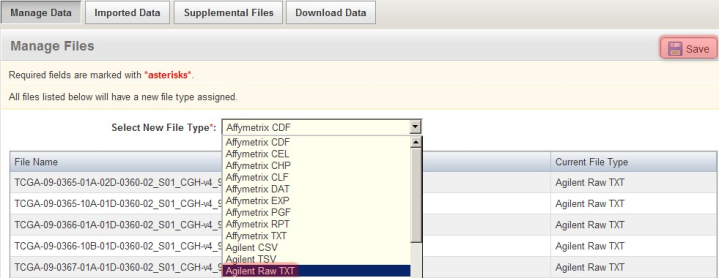
Manually specify the format of the uploaded array data files by selecting the appropriate format (Agilent Raw TXT in this example) from the 'Select New File Type' drop-down list.
...
Our next step is to validate all the files; ,which we will do so by checking off every single file in the list (IDF, SDRF, and TXT), then clicking the 'Validate' button below.
...
You'll know when the validation is successful when the status of the files shows as 'Validated' or 'Validated, Not Parsed'. (NOTE: The 'Not Parsed' status would only show in versions of caArray prior to v2.4.0 which had not yet implemented a parser for the Agilent TXT format and were thus unable to parse these files. These Either way, these files can still be imported into your experiment with or without being parsed beforehand.)
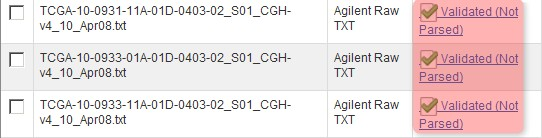
Once the data finishes validating, the 'Manage Data' tab will appear with the status of the array data files showing as 'Validated (Not Parsed)'.
...
So far, only one-sixth of the data has been uploaded. You can reproduce the procedure we followed so far to upload the data from your experiment. The procedure, summarized below, is as follows:
- Identify an IDF file from your experiment data that hasn't yet been uploaded and examine it to see which SDRF file it references
- Examine the SDRF file to see which raw TXT files it references
- Create a ZIP archive containing for each batch which contains the IDF, SDRF, and all the associated TXT files, ensuring that the size of the archive is less than 2 GB following compression.
- Upload the ZIP archive to your caArray instance
- Depending on the format of your raw array data, manually specify the file type for the array data files, as they may not automatically recognized by caArray
- Validate the uploaded files in two passes: the first, only the TXT files, and the second, all the files
- Import the validated files into the experiment
...