Page History
| Section | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Lexical Dictionaries
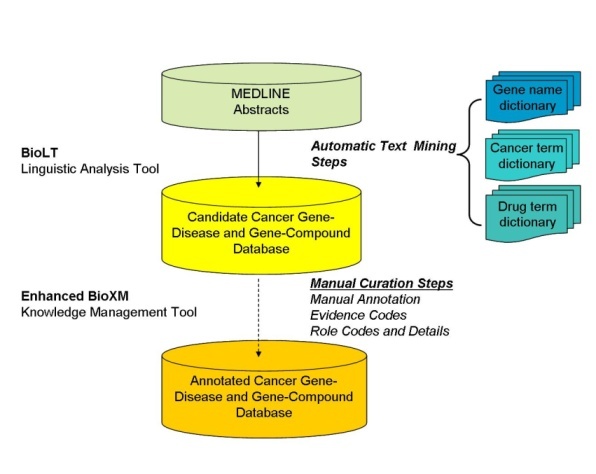
In order to mine the MEDLINE abstracts for sentences that contained information about gene-disease or gene-compound associations, lexical dictionaries were created from the NCI Thesaurus, public name catalogs, public classifications, and terms from the MEDLINE abstracts. The Compound Term Dictionary includes the NCI Thesaurus Pharmacologic Substance concept and all of its child sub-concepts, Pharmacologic Substance synonym terminologies and their sub-concepts, and any concept terminology that had the NCI Thesaurus semantic type property "Pharmacologic Substance." The Cancer Term Dictionary was created from public disease term catalogs, public disease classifications, and terms used within the literature. For the last case, terms within the publications were extracted by spelling variation identification, acronym recognition, and disambiguation procedures. Disease terms from the three sources were mapped to disease terminologies in the NCI Thesaurus and combined in a non-redundant fashion. The Cancer Term Dictionary had approximately 80,000 unique cancer disease term entries covering all of the disease terminologies from the various sources. The Gene Term Dictionary was based the union of HUGO Gene Nomenclature Committee (HGNC), LocusLink, and the Gene Database (GDB) data. These data were augmented with gene terms from the literature using sophisticated, automated procedures that identified spelling variations, acronym recognition, disambiguation, and context-based gene name recognition as described in the Biomax™ Informatics, AG Cancer Gene Index white paper. This union resulted in a total of 350,000 unique gene name entries from the three reference sources, which resolved to less than 10,000 unique genes. Each dictionary term is linked back to a unique caBIG® Enterprise Vocabulary Services (EVS) concept code. MEDLINE Abstract Text Mining
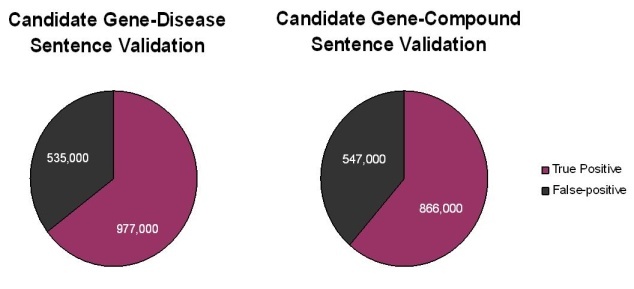
A total of 1.5 million putative gene-disease and 1.4 million putative gene-compound sentences and their PubMed Reference Identifiers were extracted by Biomax LT. Subsequent careful reading of these sentences by expert human curators showed that approximately two-thirds of the sentences extracted by the Biomax LT tool were correct. The remaining sentences were false positives that occurred not because the automated algorithm misidentified a term from the dictionaries, but rather because of context. Many of the "false" positives resulted from ambiguous acronyms (e.g., HCC can be FAM 126A gene synonym or hepatocellular carcinoma disease name) or from gene names being synonymous for multiple gene concept codes (e.g., p63 is a valid synonym for the three concepts TP63, CKAP4, and UVRAG).
Knowledge Management
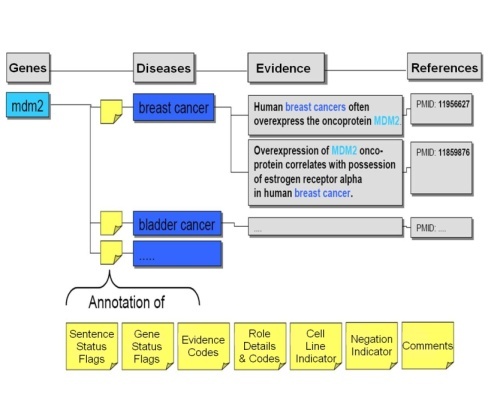
Ph.D.-level curators carefully read each sentence to validate that the sentence truly contained evidence of gene-disease or gene-compound associations. The curators also annotated sentences with descriptions of the nature of the gene-compound or gene-disease relationship and of the evidence in the sentence from which the relationship was determined. In addition, the curators set flags for genes (#Gene Status Flags) and sentences (#Sentence Status Flags) to describe their status, whether or not the evidence was from a cell line or was a negative finding (i.e, gene X is NOT associated with disease Y), and also often gave free-text #comments on records. This process is outlined in the following figure, which was adapted from the Biomax™ Informatics, AG Cancer Gene Index white paper.
High-Frequency Genes
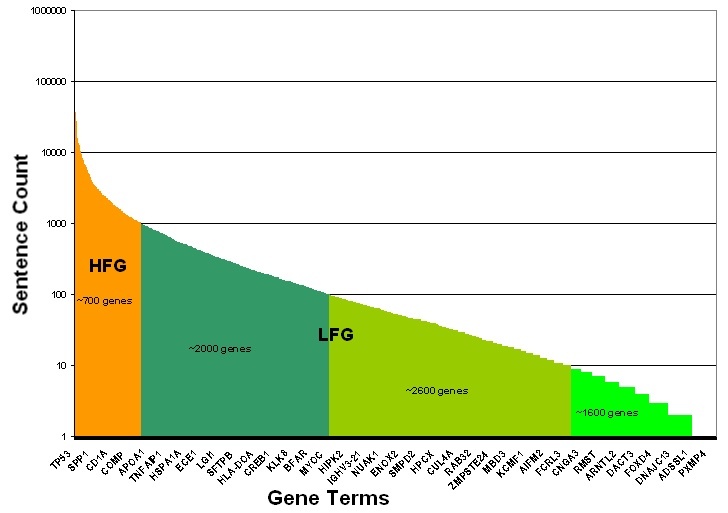
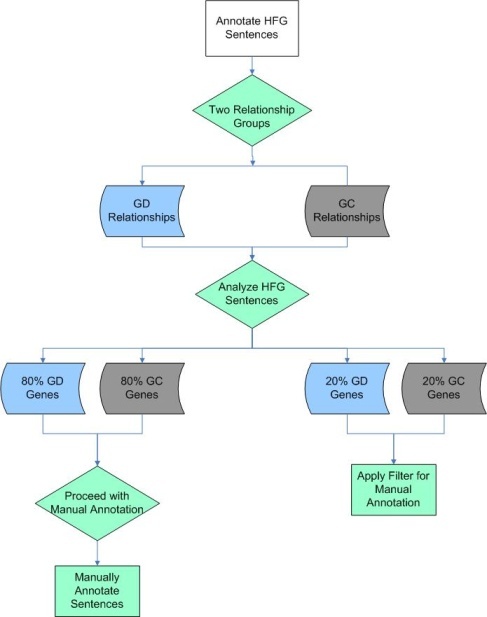
All low-frequency genes were validated and annotated by expert curators as described above. Because in some cases, high-frequency genes had thousands of associated sentences, manual curation for all of these sentences was not feasible. A rational filtering approach, shown in the flowchart below, was therefore applied to the sentences describing high frequency gene relationships. The sentences containing information about a high frequency gene were categorized as having gene-disease (GD, blue shapes), gene-compound (GC, gray shapes) relationship, or in some cases, both (green shaps). Analysis showed that ~80% of the sentences describing gene-disease or gene-compound associations could be fully manually annotated. The remaining ~20% of sentences could not easily be fully manually annotated, because there were too many associated sentences to complete the manual steps in a reasonable time frame, as illustrated in the following two figures.
High Frequency Gene Filtering
Once filtering of gene-disease sentences was complete, a similar procedure was followed for sentences with gene-compound associations. Natural language processing analysis of these candidate sentences showed that the vast majority of these associations could be classified as describing Binding (A*), Regulation (B*), and Resistance (C*). Sentences where binding, regulation, and resistance co-occur were all manually annotated. Sentences with an occurrence of one or two of the categories were filtered with the impact factor and publication date criteria, as before. Please refer to the High Frequency Gene Filtering Workflow page to view the filtering flowchart. Generation of Cancer Gene Index Gene-Disease and Gene-Compound XMLSentence validation information and annotations were added by the human curators to the BioXM database, and flags were set by the curators to indicate where in the this process each sentence and gene fell. Sentence flags indicated that the sentence had been reviewed and whether annotation was complete. Gene flags indicated whether annotations were complete for all gene-disease or gene-compound sentences that include the gene concept (e.g., inclusive of all synonyms and nomenclature variations). The final Cancer Gene Index Gene-Disease and Gene-Compound XML files were created from this database. Relationship of the Cancer Gene Index to the National Cancer Institute, caBIG®, Biomax™ Informatics AG, and Sophic Systems Alliance, Inc.The NCI established caBIG® to accelerate the discovery of efficacious methods for cancer detection, diagnostics, treatment, and prevention in order to ultimately improve patient outcomes. caBIG® is a network that links researchers, physicians, and patients throughout the cancer community and that provides standard data elements, rules, terminologies, and vocabularies to facilitate the sharing of data and information through interoperable infrastructure. These terminology and vocabulary standards are implemented in the Cancer Gene Index, as well as in a variety of interoperable, reference life science and clinical research data management and analysis software applications. The Cancer Gene Index was created by the contractors Biomax™ Informatics AG and their partner Sophic Systems Alliance, Inc., with additional project management and oversight by the NCI and SAIC-Frederick. A complete attribution is available in Credits and Resources. |