Page History
...
- A task is defined (the output). In our context, this could be segmentation of a lesion or organ, classification of an imaging study as being benign or malignant, prediction of survival, classification of a patients as being a responder or non-responder, pixel/voxel level classification of tissue or tumor grading.
- A set of images are provided (the input). These images are chosen to be of a sufficient size and diversity to reflect the challenges of the clinical problem. Data is typically spilt split up into training and test datasets. The "truth" is made available to the participants for the training data but not the test data. This reduces the risk of overfitting the data and ensures the integrity of the results.
- An evaluation procedure is clearly defined; given the output of an algorithm on a the test images, one or more metrics are computed that measure the performance, usually a reference output is used in this process, but it could also be a visual evaluation of the results by human experts)
- Participants apply their algorithm to all data in the public test dataset provided. They can estimate their performance on the training test.
- Some challenges have an optional leaderboard phase where a subset of the test images is made available to the participants ahead of the final test. Participants can submit their results to the challenge system and have them evaluated or ranked but these are not considered the final standing.
- The reference standard or "ground truth" is defined using methodology clearly described to the participants but is not made publicly available in order to ensure that algorithm results are submitted to the organizers for publication rather than retained privately.
- Final valuation is carried out by the challenge organizers on the test set where the ground truth is sequestered from the participants.
...
There were 3 sub-challenges within the radiology challenge. The primary goal of the radiology challenge was to perform segmentation from multimodal MRI of brain tumors. T1 (pre- and post constrast-contrast), T2 and FLAIR MRI images were preprocessed (registered and resampled to 1mm isotropic) by the organizers and made available. Ground truth in the form of label maps (4 color –enhancing, necrosis, non-enhancing tumor and edema) were also provided for the training images in .mha format. Additional sub-tasks included longitudinal evaluation of the segmentations for patients who had imaging from multiple time points. Finally, the third subtask was to classify the tumors into one of the three classes (Low Grade II, Low Grade III, and High Grade IV glioblastoma multiforme (GBM)). However, sub-tasks 2 and 3 were primarily pushed out to future years.
...
- The agreement between experts in not perfect (~0.8 Dice score)
- The agreement (between experts and between algorithms) is highest for the whole tumor and relatively poor for areas of necrosis and non-enhancing tumor
- Combining segmentations created by "best" algorithms created a segmentation that achieves overlap with consensus "expert" labels that approaches inter-rater overlap
- This approach can be used to automatically create large labeled datasets
- However, cases where this does not work and we still need to validate a subset of images with human experts
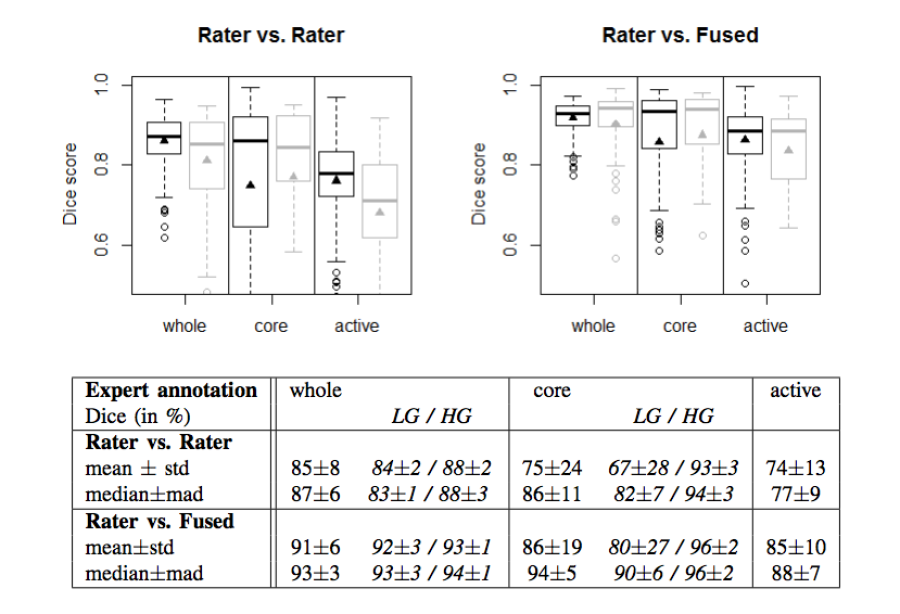
Figure 2. Dice coefficients of inter-rater agreement and of rater vs. fused label maps
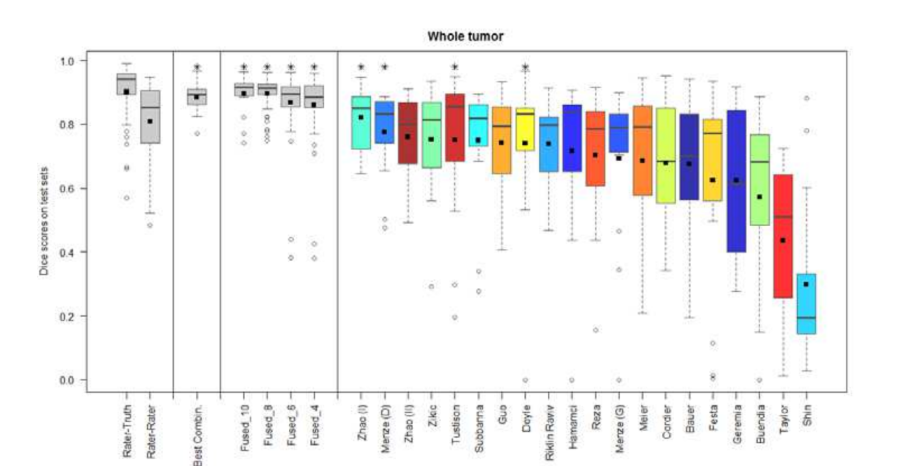
Figure 3. Dice coefficients of individual algorithms and fused results indicating improvement with label fusion
...
Below is a workflow diagram that describes the various stakeholders in the challenge and their tasks.
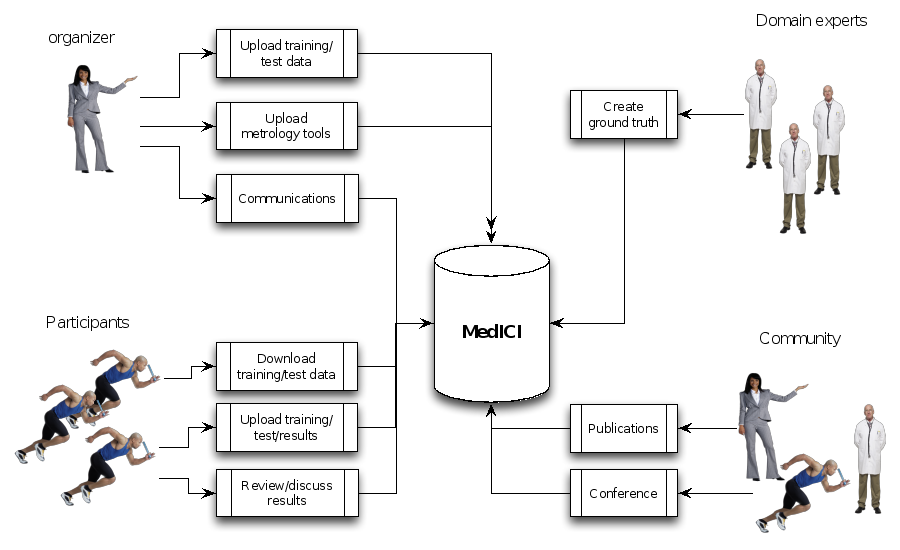
Figure 4. Challenge stakeholders and their tasks
...