Page History
...
- Select the study whose data you want to analyze in the upper right portion of the caIntegrator page. You must select a study saved as a subject annotation study, but which has genomic data.
- Click GenePattern Analysis in the left sidebar of caIntegrator. This opens the GenePattern Analysis Status page.
- In the GenePattern Analysis Status page, select Comparative Marker Selection (Grid Service) from the drop down list and click New Analysis Job. This opens the Comparative Marker Selection Analysis page, shown in the following figure.
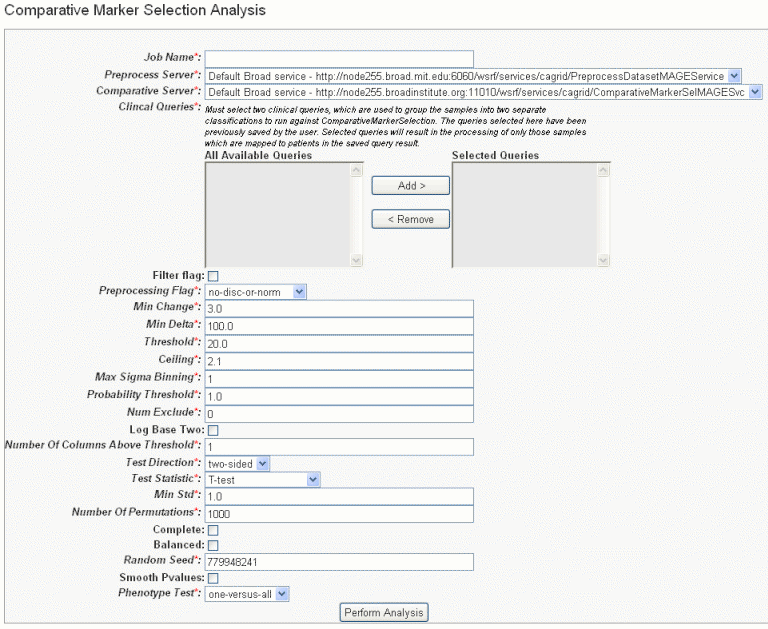
- Select or define CMS analysis parameters, described in the following table. An asterisk indicates required fields. The default settings are valid; they should provide valid results.
CMS Parameter
Description
Job Name*
Assign a unique name to the analysis you are configuring.
Preprocess Server*
A server which hosts the grid-enabled data GenePattern PreProcess Dataset module. Select one from the list and caIntegrator will use the selected server for this portion of the processing.
Comparative Server*
A server which hosts the grid-enabled data GenePattern Comparative Marker Selection module. Select one from the list and caIntegrator will use the selected server for this portion of the processing.
Annotation Queries and Lists*
All subject annotation queries and gene lists with appropriate data for the analysis are listed. Select and move two or more queries from the All Available Queries panel to the Selected Queries panel using the Add > and Remove < buttons.
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="29cd666ec1bf8b48-5c182d3e-41a544df-8fda8aed-fd7a8652e6951f02728b00e2"><ac:plain-text-body><![CDATA[Note: The [SL] and [Q] prefixes to list names indicate "Subject Lists" or "Saved Queries". A "G" in the prefix indicates the list is Global. For more information, see [Creating a Gene or Subject Listhttps://wiki.nci.nih.gov/x/FoDnAg#4-ViewingQueryResults-CreatingaGeneorSubjectList].
]]></ac:plain-text-body></ac:structured-macro>
Filter Flag
Variation filter and thresholding flag
Preprocessing Flag*
Discretization and normalization flag
Min Change*
Minimum fold change for filter
Min Delta*
Minimum delta for filter
Threshold*
Value for threshold
Ceiling*
Value for ceiling
Max Sigma Binning*
Maximum sigma for binning
Probability Threshold*
Value for uniform probability threshold filter
Num Exclude*
Number of experiments to exclude (max & min) before applying variation filter
Log Base Two
Whether to take the log base two after thresholding; default setting is "Yes".
Number of Columns Above Threshold*
Remove row if n columns are not >= than the given threshold
In other words, the module can remove rows in which the given number of columns does not contain a value greater or equal to a user defined threshold.Test Direction*
The test to perform (up-regulated for class0; up-regulated for class1, two sided). By default, Comparative Marker Selection performs the two-sided test.
Test Statistic*
Select the statistic to use.
Min Std*
The minimum standard deviation if test statistic includes the min std option. Used only if test statistic includes the min std option.
Number of Permutations*
The number of permutations to perform. (Use 0 to calculate asymptotic P-values.) The number of permutations you specify depends on the number of hypotheses being tested and the significance level that you want to achieve (3). The greater the number of permutations, the more accurate the P-value.
Complete – Perform all possible permutations. By default, complete is set to No and Number of Permutations determines the number of permutations performed. If you have a small number of samples, you might want to perform all possible permutations.
Balanced – Perform balanced permutationsRandom Seed*
The seed for the random number generator.
Smooth P-values
Whether to smooth P-values by using the Laplace's Rule of Succession. By default, Smooth P-values is set to Yes, which means P-values are always less than 1.0 and greater than 0.0.
Phenotype Test*
Tests to perform when class membership has more than 2 classes: one versus-all, all pairs.
Note: The P-values obtained from the one-versus-all comparison are not fully corrected for multiple hypothesis testing. - When you have completed the form, click Perform Analysis.
...
- Select the study whose data you want to analyze in the upper right portion of the caIntegrator page. You must select a study with copy number (either Affymetrix SNP or Agilent Copy Number) data.
- Click GenePattern Analysis in the left sidebar of caIntegrator. This opens the GenePattern Analysis Status page.
- In the GenePattern Analysis Status page, select GISTIC (Grid Service) from the drop down list and click New Analysis Job. This opens the GISTIC Analysis page, shown in the following figure.
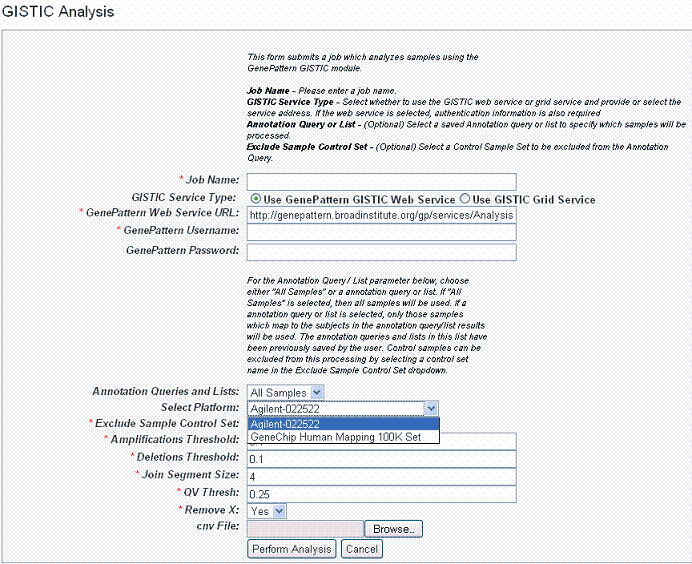
- Select or define GISTIC analysis parameters, described in the following table. You must indicate a Job Name, but you can accept the other default settings, which are valid and should produce valid results. Asterisks identify required fields. *
GISTIC Parameters
Description
Job Name*
Assign a unique name to the analysis you are configuring.
GISTIC Service Type*
Select whether to use the GISTIC web service or grid service and provide or select the service address. If the web service is selected, authentication information is also required
GenePattern User Name/Password
Include these to log into GenePattern for the analysis.
Annotation Queries and Lists
All annotation queries display in this list as well as an option to select all non-control samples. Select an annotation query if you wish to run GISTIC on a subset of the data and select all non-control samples if wish to include all samples.
Select Platform
This option appears only if more than one copy number platform exists in the study. Select the appropriate platform from the drop-down list ().
Exclude Sample Control Set
From the drop-down list, select the name of the control set you want to exclude from the analysis. Click None if that is applicable.
Amplifications Threshold*
Threshold for copy number amplifications. Regions with a log2 ratio above this value are considered amplified. Default = 0.1.
Deletions Threshold*
Threshold for copy number deletions. Regions with a log2 ratio below the negative of this value are considered deletions. Default = 0.1.
Join Segment Size*
Smallest number of markers to allow in segments from the segmented data. Segments that contain fewer than this number of markers are joined to the neighboring segment that is closest in copy number. Default = 4.
<ac:structured-macro ac:name="unmigrated-wiki-markup" ac:schema-version="1" ac:macro-id="38bec7a695e9868e-18520c62-4fd04478-892b99ec-8679017fd3ae6fb5898882ba"><ac:plain-text-body><![CDATA[
QV Thresh[hold]*
Threshold for q-values. Regions with q-values below this number are considered significant. Default = 0.25.
]]></ac:plain-text-body></ac:structured-macro>
Remove X*
Flag indicating whether to remove data from the X-chromosome before analysis. Allowed values = {1,0}. Default = 1(yes).
cnv File
This selection is optional.
Browse for the file. There are two options for the CNV file.
Option #1 enables you to identify CNVs by marker name. Permissible file format is described as follows:
A two column, tab-delimited file with an optional header row. The marker names given in this file must match the marker names given in the markers_file. The CNV identifiers are for user use and can be arbitrary. The column headers are:
Marker Name*
CNV Identifier|
Option #2 enables you to identify CNVs by genomic location. Permissible file format is described as follows:
A 6 column, tab-delimited file with an optional header row. The 'CNV Identifier', 'Narrow Region Start' and 'Narrow Region End' are for user use and can be arbitrary. The column headers are:
CNV Identifier
Chromosome
Narrow Region Start
Narrow Region End
Wide Region Start
Wide Region End - When you have completed the form, click Perform Analysis.
- When the job is complete, the system displays a completion date on the GenePattern Analysis status page. Click the Download link. This downloads zipped result files to your local work station. The number of files and their file type will vary according to the processing. The results format is compatible with GenePattern visualizers and can be uploaded within GenePattern.
- Additionally, upon completion of a successful GISTIC anaylsis, caIntegrator automatically displays the two gene lists that it generates in the Gene List Picker so that you can use them in a caIntegrator query or plot calculation. The lists are visible only to your userID. For more information, see #Choosing Genes. The genes will also display in Saved Copy Number Analyses in the left sidebar. See on #Editing a GISTIC Analysis.
Warning title Caution If samples from a copy number source are deleted, the GISTIC job in which they are appear is also deleted.
...