We advertise our Searches as being 'extensions', but in reality it is very difficult (or impossible) for a use to create a plug-in type Search.
Author: Traci St.Martin/Craig Stancl
Email: stmartin.traci@mayo.edu
Team: LexEVS/EVS
Contract: SAIC Subcontract#28XS112
Client: NCI CBIIT
National Institutes of Heath
US Department of Health and Human Services
Sign off |
Date |
Role |
CBIIT or Stakeholder Organization |
Reviewer's Comments (If disapproved indicate specific areas for improvement.) |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
The purpose of this document is to collect, analyze, and define high-level needs for and designed features of the [Product or Component Name x.x]. The focus is on the functionalities proposed by the stakeholders and target users to make a better product. The use case documents show in detail how the features meet these needs.
Design Scope
GForge items
Please visit the LexEVS 5.1 Scope document found at: https://wiki.nci.nih.gov/display/EVS/LexEVS+5.1+Scope+document
Solution Architecture
Proposed technical solution to satisfy the following requirements:
- Query Performance Enhancements - Improve the API to support the needs of the Metathesaurus Browser's query response.
- Metathesauraus Content (RRF) - Improve the loader to support full loading of RRF data as necessary for proper operation of the Methathesaurus Browser.
- Value Domain Support - Address an important part of the Semantic Infrastructure that is needed in caBIG.
- Improved Loader Framework - Improve the loading capability and allow loaders to be modular.
High Level Architecture
The LexEVS 5.1 infrastructure exhibits an n-tiered architecture with client interfaces, server components, domain objects, data sources, and back-end systems (Figure 1.1). This n-tiered system divides tasks or requests among different servers and data stores. This isolates the client from the details of where and how data is retrieved from different data stores.
The system also performs common tasks such as logging and provides a level of security for protected content. Clients (browsers, applications) receive information through designated application programming interfaces (APIs). Java applications communicate with back-end objects via domain objects packaged within the client.jar. Non-Java applications can communicate via SOAP (Simple Object Access Protocol) or REST (Representational State Transfer) services.
Most of the LexEVS API infrastructure is written in the Java programming language and leverages reusable, third-party components. The service infrastructure is composed of the following layers:
Application Service layer - accepts incoming requests from all public interfaces and translates them, as required, to Java calls in terms of the native LexEVS API. Non-SDK queries are invoked against the Distributed LexEVS API, which handles client authentication and acts as proxy to invoke the equivalent function against the LexEVS core Java API. The caGrid and SDK-generated services are optionally run in an application server separate from the Distributed LexEVS API.
The LexEVS caCORE SDK services work directly against the database, via Hibernate bindings, to resolve stored objects without intermediate translation of calls in terms of the LexEVS API. However, the LexEVS SDK services do still require access to metadata and security information stored by the Distributed and Core LexEVS API environment to resolve the specific database location for requested objects and to verify access to protected resources, respectively.
From the client prospective, the LexEVS services will function as "ports" accessible through the caGrid 1.3 service architectural model. LexEVS services will follow the caGrid architecture for analytical and data services. See the caGrid 1.3 documentation for architectural details: https://cabig.nci.nih.gov/workspaces/Architecture/caGrid/
Core API layer - underpins all LexEVS API requests. Search of pre-populated Lucene index files is used to evaluate query results before incurring cost of database access. Access to the LexGrid database is performed as required to populate returned objects using pooled connections.
Data Source layer---is responsible for storage and access to all data required to represent the objects returned through API invocation.
High Level Design Diagram
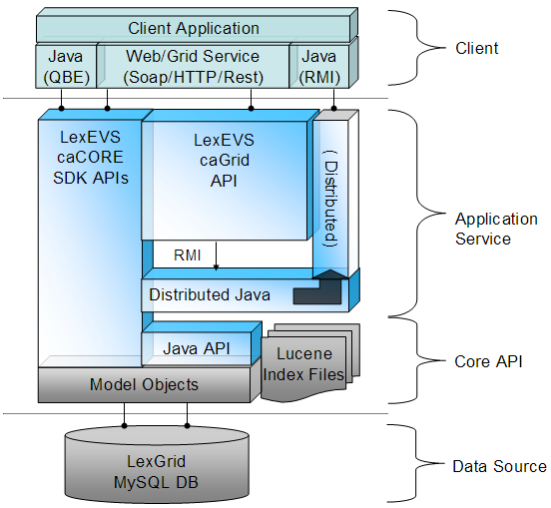
Figure 1.1 - High Level Diagram
1.0 Query Performance Enhancements
- Lucene
- Lazy Document Loading
Lucene is very fast as a search engine. Given a text string, Lucene can find matching documents in huge indexes very fast. This is the purpose and strength of Lucene. Lucene is not, however, a database. Retrieving information from the documents that the search found as 'hits' is slow.
Consider this scenario: A user searches for 'heart' in the NCI MetaThesaurus. When Lucene does its search, it will return probably 50,000+ 'hits'. This search is done very fast. LexEVS previously would retrieve all of those documents to populate the ResolvedConceptReference. Retrieving this many documents from Lucene is slow.
The solution is to is lazy load the documents as needed. After the Lucene search is complete, we only store the Document Id. Then, when information from the document is needed, it is retrieved from the document. This is helpful in Iterator-type scenarios, where retrieval can be done one at a time.
- Update to Lucene 2.4 code
As we move forward, it is important to keep current with the latest Lucene API. Not only is this important for performance reasons -- it will limit our ability to upgrade our Lucene dependencies if we rely on
deprecated methods.
- Searching
- Plug-in Search Framework
We advertise our Searches as being 'extensions', but in reality it is very difficult (or impossible) for a use to create a plug-in type Search.
The Interface org.LexGrid.LexBIG.Extensions.Query.Search will be introduced. The purpose of this interface is to give users a plug-in type Interface to implement different search strategies. This interface will accept
a text query string and output a Lucene Query.
- Sorting
- Plug-in Sort Framework
As with Searching, Sort algorithms are not currently easily extended. A well defined and 'Extension-ready' interface would allow users to add additional search functionality on demand, without rebuilding or recompiling.
The existing Interface org.LexGrid.LexBIG.Extensions.Query.Search will be expanded to allow for easy implementation and flexibility, allowing rapid creation of new Sort Algorithms and techniques.
- SQL
- SQL query optimizations to increase database performance
Join EntityDescription when building AssociatedConcepts
The 'EntityDescription' field of 'Entity' is being retrieved with a separate SQL call. This will allow the building of AssociatedConcepts with minimal calls
to the database.
Furthermore, this will allow the 'EntityDescription' to be available without requiring the actual 'CodedEntry' to be resolved. For most usescases, this should enable users to resolve Graphs with 'CodedEntryDepth=0'. Avoiding any resolving of the CodedEntry will keep resolve times to a minimum.
Join EntryState when building CodedEntry
The EntryState is now populated with a seperate SQL SELECT query to the database. This results in one SELECT statement per CodedEntry returned - and there is potential for a large number of CodedEntries to be resolved at once. Populating this with a JOIN instead of a SELECT will be more efficient and not require additional unnecessary SELECT queries to the database.
2.0 Metathesauraus Content (RRF)
3.0 Value Domain Support
Overview
The LexEVS Value Domain and Pick List service will provide ability to load Value Domain and Pick List Definitions into LexGrid repository and provides ability to apply user restrictions and dynamically resolve the definitions during run time. Both Value Domain and Pick List service are integrated part of LexEVS core API.
The LexEVS Value Domain and Pick List service will provide programmatic access to load Value Domain and Pick List Definitions using the domain objects that are available via the LexGrid logical model. The LexEVS Value Domain and Pick List service will provide ability to apply certain user restrictions (ex: pickListId, valueDomain URI etc) and dynamically resolve the Value Domain and Pick List definitions during the run time
The LexEVS Value Domain and Pick List Service meant to expose the API particularly for the Value Domain and Pick List elements of the LexGrid Logical Model. For more information on LexGrid model see http://informatics.mayo.edu\\![]()
LexEVS Value Domain and Picklist Service Class Diagram
Common Services Class Diagram
These are the classes that are used commonly across Value Domain and Pick List implementation.
Class Name |
Description |
VDEntryTypeServices |
Class to handle Entry Type objects to and fro database . |
VDEntryStateServices |
Class to handle EntryState objects to and fro database. |
VDPropertyServices |
Class to handle Property objects to and fro database. |
VDMappingServices |
Class to handle supported Mappings objects to and fro database. |
VDServiceHelper |
Helper class containing methods that are commonly used. |
VDBaseSQLServices |
Class to handle SQL Services. |
VDBaseService |
Base service class to handle all Value Domain and Pick List related objects to and fro database. |
Value Domain Class Diagram
Classes that implements LexEVS Value Domain API
Class Name |
Description |
VDSServices |
Class to handle list of Value Domain Definitions Object to and fro database |
VDServices |
Class to handle individual Value Domain Definition objects to and fro database. |
VDEntryServices |
Class to handle Value Domain Entry objects to and fro database. |
LexEVSValueDomainServices |
Primary interface for LexEVS Value Domain API |
LexEVSValueDomainServicesImpl |
Implementation of LexEVSValueDomainServices which is primary interface for LexEVS Value Domain API. |
LoadValueDomain |
Imports the value Domain Definitions in the source file, provided in LexGrid canonical format, to the LexBIG repository. |
ResolvedValueDomainCodedNodeSet |
Contains coding scheme version reference list that was used to resolve the value domain and the coded node set. |
ResolvedValueDomainDefinition |
A resolved Value Domain definition containing the coding scheme version reference list that was used to resolve the value domain and an iterator for resolved concepts. |
Picklist Class Diagram
Classes that implements LexEVS Pick List API
Class Name |
Description |
PickListsServices |
Class to handle list of Pick List Definitions. |
PickListServices |
Class to handle individual Pick List Definition objects to and fro database. |
PLEntryServices |
Class to handle Pick List Entry objects to and fro database. |
LexEVSPickListServices |
Primary interface for LexEVS Pick List API. |
LexEVSPickListServicesImpl |
Implementation of LexEVSPickListServices which is primary interface for LexEVS Pick List API. |
LoadPickList |
Imports the Pick List Definitions in the source file, provided in LexGrid canonical format, to the LexBIG repository. |
ResolvedPickListEntyList |
Class to hold list of resolved pick list entries. |
ResolvedPickListEntry |
Bean for resolved pick list entries. |
LexBIG Services Class Diagram
An interface to LexEVS Value Domain and Pick List Services could be obtained using an instance of LexBigService.
Method Name |
Description |
getValueDomainService() |
Returns an interface to LexEVS Value Domain API |
getPickListService() |
Returns an interface to LexEVS Pick List API. |
4.0 Improved Loader Framework
Cross product dependencies
Include a link to the Core Product Dependency Matrix.
Changes in technology
Include any new dependencies in the Core Product Dependency Matrix and summarize them here.
- No new dependencies exist.
Assumptions
List any assumptions.
Risks
- Increased load time and storage requirements due to additional Meta (RRF) content.
- Due to the additional content to load from RRF files, there is a risk of increased loading times and increased storage requirements. The new loader framework should mitigate the increased loading times (providing a faster load while increasing content to be loaded).
Detailed Design
Specify how the solution architecture will satisfy the requirements. This should include high level descriptions of program logic (for example in structured English), identifying container services to be used, and so on.
Query Performance Enhancements
Lucene Lazy Loading
Backgroud - Lucene Documents
Lucene stores information in Documents, and these Documents have Fields that are used to hold information. Each Document has a unique id.
For example, an index of People may be indexed in Lucene as:
Document: id 1 First Name: John Last Name: Doe Sex: Male Age: 45 Document: id 2 First Name: Jane Last Name: Doe Sex: Female Age: 40
... etc.
LexEVS stores information about Entities in this way. Property names and values, as well as Qualifiers, Language, and various other information about the Entity are held in Lucene indexes.
Backgroud - Querying Lucene
Lucene provides a Query mechanism to search through the indexed documents. Given a search query, Lucene will provide the Document id and the score of the match (Lucene assigns every match a 'score', depending on the strength of the match given the query).
So, if the above index is queried for "First Name = Jane AND Last Name = Doe", the result will be the Document id of the match (2), and the score of the match (a float number, usually between 1 and 10).
Notice that none of the other information is returned, such as Sex or Age. It is useful for that extra information to be there, because if it exists in the Lucene indexes we do not have to make a database query for it. BUT, retrieving data from Lucene Documents is expensive, just as retrieving data from a database would be.
- Lazy Retrieval
We can leverage this to increase performance in LexEVS. Consider this simplified LexEVS Entity index:Document: id 1 Code: C12345 Name: Heart Document: id 2 Code: C67890 Name: Foot Document: id 3 Code: C98765 Name: Heart Attack
If a user constructs a Query (Name = Heart*), the query will return with the matching Document ids (1 and 2). Previously, LexEVS would immediately retrieve the 'Code' and 'Name' fields from the matches, and use them to construct the results that would be ultimately returned to the user. This does not scale well, especially for general queries in large ontologies. In a large ontology, a Query of (Name = Heart*) may match tens of thousands of Documents. Retrieving the information from all these Documents is a significant performance concern.
Instead of retrieving the information up front, LexEVS will simply store the Document id for later use. When this information is actually needed by the user (for example, the information needs to be displayed), it is retrieved on demand.
Searching
To allow users to plug in custom search algorithms, the LexEVS Extension framework needed to be extended to include Searches.
The org.LexGrid.LexBIG.Extensions.Extendable.Search interface consists of one method to be implemented:
Class: org.LexGrid.LexBIG.Extensions.Extendable.Search |
Method: public org.apache.lucene.search.Query buildQuery(String searchText) |
This enables the user to construct any type of Query given search text. Wildcards may be added, search terms may be grouped, etc.
Algorithms
More precice DoubleMetaphoneQuery
DoubleMetaphoneQueries enable the user to input incorrectly spelled search text, while still returning results. Because this is a 'fuzzy' search, it is important to structure the Query in a way that the most appropriate results are returned to the user first.
For example, the Metaphone computed value for "Breast" and "Prostrate" is the same. Given the search term "Breast", both "Breast" and "Prostrate" will match with exactly the same score. Technically, this is correct behavior, but to the end user this is not desirable. To overcome this, we have introduced a new query, WeightedDoubleMetaphoneQuery.
WeightedDoubleMetaphoneQuery
This algorithm does not automatically assume that the user has spelled the terms incorrectly. Searches are also based on the actual text that the user has input, along with the Metaphone value.
Again, if the user input "Breast", the query will still match "Breast" and "Prostrate", but "Breast" will have a higher match score, because the actual user text is considered. This will add a greater precision to this fuzzy-type query.
Algorithm
1: get: user text input 2: total score = 0 3: metaphone score = 0 4: actual score = 0 5: metaphone value = lucene.computeMetaphoneValue(user text input) 6: metaphone score = lucene.scoreMetaphoneValue(metaphone value) 7: actual score = lucene.score(user text input) 8: total score = metaphone score + actual score 9: halt
Case-insensitive substring
SubStringSearch - This algorithm is intended to find substrings within a large string. For example:
"with a heart attack"
Will match:
"The patient with a heart attack was seen today".
Also, a leading and trailing wildcard will be added, so
"th a heart atta"
Will also match:
"The patient wi*th a heart atta*ck was seen today".
Algorithm
1: get: user text input 2: user text input = '*' + user text input + '*' 3: score = lucene.score(user text input) 4: halt
Metathesauraus Content (RRF)
Value Domain Support
Improved Loader Framework
Implementation Plan
This will include the technical environment (HW,OS, Middleware), external dependencies, teams/locations performing development and procedures for development (e.g. lifecycle model,CM), and a detailed schedule.
Technical environment
No new environment requirements exist for the the LexEVS 5.1, with the exception of additional storage to accommodate larger content loads.
Software (Technology Stack)
Operating System
- Linux (though no operating system dependencies currently exist)
Application Server
- JBoss 4.0.5
Database Server
- MySQL 5.0.45
Other Software Components
- caGrid 1.3 / Globus 4.0.3
Server Hardware
Server
- NCI standard hardware.
Minimum Processor Speed
- Minimum required by JBoss.
Minimum Memory
- Minimum required by JBoss.
Storage
Expected file server disk storage (in MB)
- 200GB (May increase due to additional RRF content load)
Expected database storage (in MB)
- 100GB (May increase due to additional RRF content load)
Networking
Application specific port assignments
- Standard port required by JBoss to externalize LexEVS grid service. May be assigned any suitably available port #.
JBoss Container Considerations
There are specific requirements for JBoss containers for LexEVS 5.1.
In order to support multiple versions of LexEVS (for example 5.0 and 5.1), there are JBoss considerations.
- Both lexevsapi 5.0 and 5.1 in the same container. This means that both http://lexevsapi.nci.nih.gov/lexevsapi50 and http://lexevsapi.nci.nih.gov/lexevsapi51 can exist in the same Jboss container.
- Grid services can NOT be in the same JBoss container because of naming - they both need to be named /wsrf in the container. This results in the use of 1 JBoss container for LexEVS 5.0 and 1 JBoss container for LexEVS 5.1.
External dependencies
N/A
Team/Location performing development
- Traci St. Martin / Mayo Clinic
- Craig Stancl / Mayo Clinic
- Scott Bauer / Mayo Clinic
- Kevin Peterson / Mayo Clinic
- Sridhar Dwarkanath / Mayo Clinic
- Michael Turk / Mayo Clinic
Procedures for Development
Development will follow procedures as defined by NCI.
Detailed schedule
The LexEVS 5.1 project plan is located in Gforge at: LexEVS 5.1 Project Plan and LexEVS 5.1 Project Plan (PDF)
The LexEVS 5.1 BDA Project plan is located at: LexEVS 5.1 BDA Project Plan
Training and documentation requirements
N/A
Download center changes
N/A