Page History
| Scrollbar | ||
|---|---|---|
|
...
| Page info | ||||
|---|---|---|---|---|
|
This chapter describes the processes for creating and managing studies in caIntegrator. Topics in this chapter include:
...
One of the most important tasks in creating a study in caIntegrator is in properly annotating the data. Each annotation has a definition you must identify. Because the process can be quite complex, you might want to review the following steps for working with annotations.
Annotation Workflow Summary
...
- Add an annotation group. This optional step is for users who have a rigid data dictionary of all annotations relevant to the study. This step can also be helpful in cases where a study has many annotations. For more information, see Adding an Annotation Group.
- Add subject annotation data. This consists of multiple sub-steps.
- Add a new subject annotation data sources file. This step uploads the file containing annotations and starts the workflow for assigning uploaded data definitions. See Editing an Annotation Group, step 1.
- Edit the annotations. This step opens the Define Fields for Subject Data page. See Editing an Annotation Group, step 2.
- In the Define Fields for Subject Data page, review possible definitions in the annotation group associated with this study. See Define Fields Page.
- Assign the visibility of each annotation definition. See Editing an Annotation Group, step 2.
- In the authorization column, select the annotation or annotations to be used to restrict data by subject for authorized groups. If authorization groups are to be used to restrict study data, at least one annotation authorization must be selected. If authorization groups are not to be used to restrict study data, selecting an annotation authorization is not necessary. Annotations used to restrict data by subject must contain permissible values. See Assigning an Identifier or Annotation for more information about permissible values.
- Locate and verify the assignment as "identifier" for one annotation. See Assigning an Identifier or Annotation.
- Review, verify and assign definitions for each annotation. You can do this in one of four ways:
--Accept existing default definitions as described in the associated annotation group. See Assigning an Identifier or Annotation.
--Create or manage definitions manually. See Assigning an Identifier or Annotation.
--Search for and use definitions existing in other caIntegrator studies. See Searching for Annotation Definitions.
--Search for and use definitions from caDSR. See Searching for Annotation Definitions.
- Load the Subject Annotation Source. Up until this point, you can periodically save your work with the annotations, but before you can deploy the study, you must complete this step.
- Deploy the study.
Adding an Annotation Group
| Info | ||
|---|---|---|
| ||
This optional step is for users who have a rigid data dictionary of all annotations relevant to the study. This step can also be helpful in cases where a study has many annotations. |
This topic opens from both the Create Annotation Group page and the Edit Annotation Group page. If you plan to create a group, continue with this topic. If you plan to edit an existing annotation group, see Editing an Annotation Group.
An annotation group is a group of annotation definitions configured in a subject data source CSV file. This feature is primarily meant for the Study Manager who knows that they have tightly restricted vocabulary definitions that are relevant to a study. In this optional step, you can review the uploaded Group Definition Source file before assigning the appropriate definitions for your study.
...
- On the Edit Study page for a study, Annotation Groups section, click the Add New button.
- On the Edit Annotation Group page that opens, enter a name for the annotation group.
- Enter a description (optional).
- Browse for the Group Definition Source CSV file.
The CSV file must include columns with these column headers in the first row: File Column Name, Field Type, Entity Type, CDE ID, CDE Version, Annotation Def Name, Data Type, Permissible, and Visible. Subsequent rows in the file define each subject annotation column in the subject annotation file.- If a subject annotation is defined by a CDE Public ID, values for the following columns are required: File Column Name, Field Type, Entity Type, CDE ID, and Visible; a value for CDE Version is optional.
OR - If a subject annotation definition is not defined by a CDE Public ID, values for the following columns are required: File Column Name, Field Type, Entity Type, Annotation Def Name, Data Type (String, Date, Numeric), Permissible (Yes or No), and Visible (Yes or No).
- If a subject annotation is defined by a CDE Public ID, values for the following columns are required: File Column Name, Field Type, Entity Type, CDE ID, and Visible; a value for CDE Version is optional.
- Click Save. This uploads the file, whose name now displays on the Edit Study page under Annotation Groups.
When you open the Define Fields for Subject Data page, the annotation definitions in the file you uploaded display on the page, available for assignment in the study. Additionally, you can view the definitions by viewing the annotation group listed in the first column of the matrix.
...
The Edit Study page, described in Creating or Editing a Study, opens after you save a new study or click to edit an existing studyan existing study.
| Warning | ||
|---|---|---|
| ||
When following the steps in this section, if you have not manually created Annotation Groups, you MUST check Create a new annotation definition if one is not found. |
To add subject annotation metadata on this page, follow these steps:
...
- For the column that you choose to be the one and only Identifier column (in this case, PatientID), in the Column Type drop-down list, select Identifier. The following figure shows the dialog box rendering when "identifier" is selected in the Field Descriptor Type drop-down list.
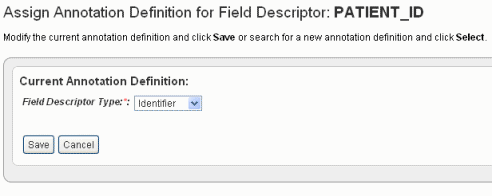
- Click Save to save the identifier. This returns you to the Define Fields for Subject Data page where the Identifier is noted in the Annotation Definition column.
- After you have defined which field is the Identifier, you must ensure that ALL other data fields also have an annotation definition assignment. For those fields without an annotation definition assignment or for those whose annotation definition you want to review, click Change Assignment.
- In the Assign Annotation Definition for Field Descriptor dialog box, shown in the following figure, select Annotation in the drop-down list.
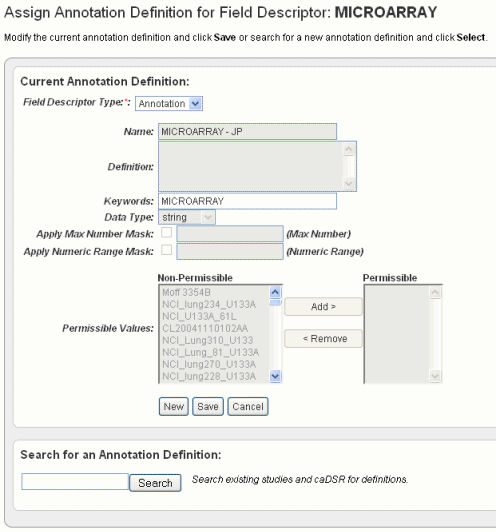
As you select the column type, you can work with column headers in one of four ways in this dialog box.- You can accept existing default definitions (those that are inherent in the data file you selected). See Step 5.
- You can create and/or manage your own definitions manually. See Step 6.
- You can search for and use definitions in other caIntegrator studies. See Searching for Annotation Definitions.
- You can search for and use definitions found in caDSR. See Searching for Annotation Definitions.
- Review the current annotation definition in the Assign Definition page, Current Annotation Definition section. Click Cancel to return to the Define Fields... page.
You can still initiate a search for another annotation definition in the Search for an Annotation Definition section on the browser page if you choose to change the definition. See the bottom section of the preceding figure. See also Searching for Annotation Definitions. Click Save to retain any changes. To enter a new name annotation, or any other information about the annotation definition, click the New button and enter the information described in the following table.
Annotation Field
Field Description
Name
Enter the name for the annotation.
Definition
Enter the term(s) that define the annotation.
Keywords
Insert keyword(s) that could be used to find the annotation in a search, separated by commas.
Data Type
Select a string (default), numeric, or date.
Apply Max Number Mask
This field is available only for numeric-type annotations, or when a new definition is created. This feature is unavailable when permissible values are present.
Select the box and enter a maximum number for the mask, such as "80" for age. When you query results above the value of the mask, then the system displays the mask and not the actual age.Tip title Tip If you enter masks of both "max number" and "range", caIntegrator applies both masks at the same time.
The Data Dictionary page now has a Restrictions column that shows restrictions whenever a mask has been applied.Apply Numeric Range Mask
This field is available only for numeric-type annotations, or when a new definition is created. This feature is unavailable when permissible values are present.
Select the box and enter a width of range for the mask, such as "5" representing blocks of 5 years. For example, if you enter a width of 5, the query only allows age blocks of 0-5, 6-10, 11-15, etc.
When you query results above the value of the mask, then the system displays the mask and not the actual age ranges.Tip title Tip If you enter masks of both "max number" and "range", caIntegrator applies both masks at the same time.
The Data Dictionary page now has a Restrictions column that shows restrictions whenever a mask has been applied.Permissible/Non-permissible Values
Tip title Tip The first time you load a file, before you assign annotation definitions, step #3 in Assigning an Identifier or Annotation, these panels may be blank. If the column header for the data is already "recognizable" by caIntegrator, the system makes a "guess" about the data type and assigns the values to the data type in the newly uploaded file. They will display in the Non-permissible values sections initially. Use the Add and Remove buttons to move the values shown from one list to the other, as appropriate.
Warning title Required values Note that for all annotations you want to appear, you MUST select the Permissible values. To do this, select Change Assignment, as described in step 3 and click the New button on the page that opens. As you are describing each annotation, be sure to add the permissible valudes and move them as described in this table cell. Click Save.
When you select or change annotation definitions by selecting matching definitions (described in Searching for Annotation Definitions), this may add (or change) the list of non-permissible values in this section.
...
You, as the caIntegrator study manager, must create a Subject to Sample mapping file and then import it into caIntegrator before following the actual mapping steps. This file provides caIntegrator with the information for mapping patients to caArray samples.
- If you are starting with parsed data, the mapping file will have 2 columns. If you are working with unparsed data, the mapping file will have 6-column columns. See step 3 below for more information. The six columns that may be part of your file are Start with the 6-column mapping file template, described as follows:
- All platforms – Raw (level 1) data cannot be mapped; only normalized, processed (level 2) data is acceptable.
- The required six-column file format uses the following columns:
- Subject ID
- Sample ID
- Name of supplemental file (if appropriate, as attached to the experiment in caArray)
- Probe Header – Name of column header (in the supplemental file) which contains the probe IDs.
- Value Header – Name of column header (in the supplemental file) which holds the level 2 data.
Sample Header– Name of column header (in the supplemental file) which holds the level 2 data.
Info title Last two columns Only one of the last 2 columns is used: a single sample per file uses the Value Header column; multiple samples per file used Sample Header column. Unused columns are blank.
The following figure shows an example multiple sample mapping file in CSV format.
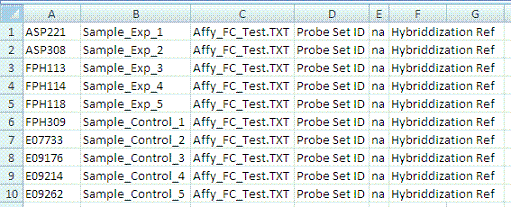
- When you use the mapping file, make sure you use the subject ID for mapping. If the file is human data, the subject ID is the patient ID.
- Determine whether your data in from caArray is "imported and parsed" or "supplemental". These are the 'Loading Types' referred to in Step 4 3 of Steps for Mapping Genomic Data. Fill in the 2-column or 6-column mapping file according to the following standard:
- Imported and parsed – Complete only the first two columns of the 6-column mapping file as described above. You can ignore the remaining columns.This mapping file for parsed data has only two columns, Subject ID and Sample ID, without a header.
Supplemental– Supplemental data files comes in two types: "single sample per file" and "multiple samples per file". In either case, only one of the last two columns is used. If the supplemental data format is , single sample per file, the column named "Sample_Header" can be left empty. If the supplemental data format is multiple samples per file, the column named "Value_Header" can be left empty.
Info title Configuring supplemental files Supplemental files from caArray for mapping data must be configured appropriately. For information, see Supplemental Files Configuration.
The following steps use data of either type.
...
Click an external link to open a page that displays appropriately formatted web page links; an example is shown in the following figure.

Activating User Group Authorization
Deploying the Study
When you are ready to deploy the study, click the Deploy Study button on the Edit Study page. caIntegrator retrieves the selected data from the data service(s) you defined and makes the study available to a study manager or to anyone else who may want to analyze the study's data. Using the Manage Studies feature, you can then configure and share data queries and data lists with all investigators who access the study.
Note that you can continue to work in caIntegrator while the study is being deployed.
...
| Scrollbar | ||
|---|---|---|
|