Page History
...
- Start with the 6-column mapping file template, described as follows:
- All platforms – Raw (level 1) data cannot be mapped; only normalized, processed (level 2) data is acceptable.
- The required six-column file format uses the following columns:
- Subject ID
- Sample ID
- Name of supplemental file (if appropriate, as attached to the experiment in caArray)
- Probe Header – Name of column header (in the supplemental file) which contains the probe IDs.
- Value Header – Name of column header (in the supplemental file) which holds the level 2 data.
Sample Header– Name of column header (in the supplemental file) which holds the level 2 data.
Info title Last two columns Only one of the last 2 columns is used: a single sample per file uses the Value Header column; multiple samples per file used Sample Header column. Unused columns are blank.
The following figure shows an example multiple sample mapping file in CSV format.
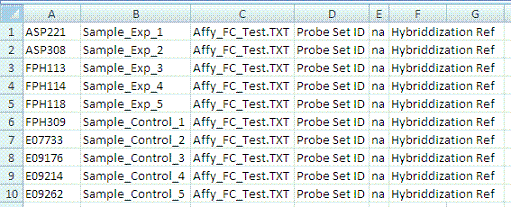
- When you use the mapping file, make sure you use the subject ID for mapping. If the file is human data, the subject ID is the patient ID.
- Determine whether your data in caArray is "imported and parsed" or "supplemental". These are the 'Loading Types' referred to in Step 4 of Steps for Mapping Genomic Data. Fill in the 6-column mapping file according to the following standard:
- Imported and parsed – Complete only the first two columns of the 6-column mapping file as described above. You can ignore the remaining columns.This mapping file for parsed data has only two columns, Source ID and Subject ID, without a header.
Supplemental– Supplemental data files comes in two types: "single sample per file" and "multiple samples per file". In either case, only one of the last two columns is used. If the supplemental data format is, single sample per file, the column named "Sample_Header" can be left empty. If the supplemental data format is multiple samples per file, the column named "Value_Header" can be left empty.
Info title Configuring supplemental files Supplemental files from caArray for mapping data must be configured appropriately. For information, see Supplemental Files Configuration.
The following steps use data of either type.
...