Page History
...
- Enter or change (if editing) the name and/or description.
- Select or verify the checkbox to specify if you want to allow public access to the study.
- For the study log feature, click View Log or Edit Log. See Study Log for details about the log.
- Click Save.
Info title Note You can save the study at any point in the process of creating it. You can resume the definition and deployment process later.
- If you choose to add a logo for the study, click the Browse button corresponding to Logo File in the upper right of the Edit Study page. Navigate for the file, and click Browse. The file type displays above the Upload Now button.
- Click the button to upload the logo. Once you save the study (or its edit), the logo displays in the center of the page. On the home page for the study, the logo displays in the upper left, above the sidebar.
...
If this Define Fields page opens after clicking the Edit Annotations button, working with this page is identical for both subject and image annotations

The MOST important steps in creating annotation definitions on this page are these:
...
- You can specify visibility of specified annotation data in the Visible column.
- Select a checkbox for a row to make the corresponding data visible to all subscribers of the study or anonymous users if the study is made available to the public.
- Clear a checkbox to hide the corresponding annotation from any subscriber or anonymous user of the study. Data continues to exist but does not show up in query fields nor in query results.
- The Annotation Header from File column on the Define Fields for Subject (or Image) Data page (the figure shown above) displays column headers taken from the source CSV file. The Define Fields... page also displays data values in the file you have designated. You must map each column name to an existing column name in the caIntegrator database or in caDSR. If it doesn't yet exist, you can create a custom column name. The following figure is an example CSV file whose data you would be mapping in caIntegrator in the Define Fields page.
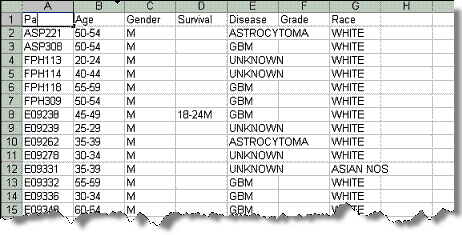
- To indicate the unique identifier of choice, on the row showing the column header (PatientID in the figure, but other examples are subject identifier, sample identifier, etc), click Change Assignment in the Annotation Definition column.
...
- For the column that you choose to be the one and only Identifier column (in this case, PatientID), in the Column Type drop-down list, select Identifier. The following figure shows the dialog box rendering when "identifier" is selected in the Field Descriptor Type drop-down list.
- Click Save to save the identifier. This returns you to the Define Fields for Subject Data page where the Identifier is noted in the Annotation Definition column.
- After you have defined which field is the Identifier, you must ensure that ALL other data fields also have an annotation definition assignment. For those fields without an annotation definition assignment or for those whose annotation definition you want to review, click Change Assignment.
- In the Assign Annotation Definition for Field Descriptor dialog box, shown in the following figure, select Annotation in the drop-down list.
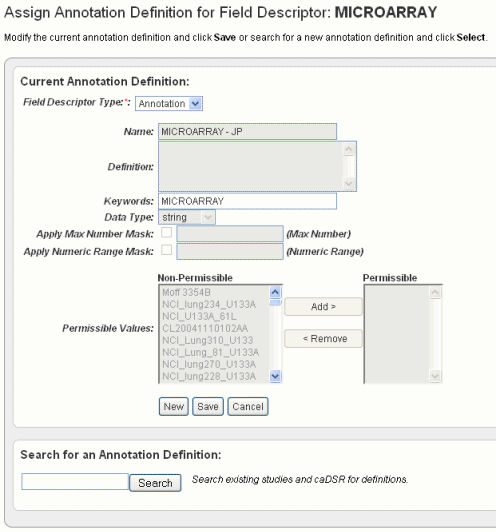
As you select the column type, you can work with column headers in one of four ways in this dialog box.- You can accept existing default definitions (those that are inherent in the data file you selected). See Step 5.
- You can create and/or manage your own definitions manually. See Step 6.
- You can search for and use definitions in other caIntegrator studies. See #Searching for Annotation Definitions.
- You can search for and use definitions found in caDSR. See #Searching for Annotation Definitions.
- Review the current annotation definition in the Assign Definition page, Current Annotation Definition section. Click Cancel to return to the Define Fields... page.
You can still initiate a search for another annotation definition in the Search for an Annotation Definition section on the browser page if you choose to change the definition. See the bottom section of the preceding figure. See also #Searching for Annotation Definitions. Click Save to retain any changes. - To enter a new name annotation, or any other information about the annotation definition, click the New button and enter the information described in the following table.
Annotation Field
Field Description
Name
Enter the name for the annotation.
Definition
Enter the term(s) that define the annotation.
Keywords
Insert keyword(s) that could be used to find the annotation in a search, separated by commas.
Data Type
Select a string (default), numeric, or date.
Apply Max Number Mask
This field is available only for numeric-type annotations, or when a new definition is created. This feature is unavailable when permissible values are present.
Select the box and enter a maximum number for the mask, such as "80" for age. When you query results above the value of the mask, then the system displays the mask and not the actual age.
Note: If you enter masks of both "max number" and "range", caIntegrator applies both masks at the same time.
The Data Dictionary page now has a Restrictions column that shows restrictions whenever a mask has been applied.Apply Numeric Range Mask
This field is available only for numeric-type annotations, or when a new definition is created. This feature is unavailable when permissible values are present.
Select the box and enter a width of range for the mask, such as "5" representing blocks of 5 years. For example, if you enter a width of 5, the query only allows age blocks of 0-5, 6-10, 11-15, etc.
When you query results above the value of the mask, then the system displays the mask and not the actual age ranges.
Note: If you enter masks of both "max number" and "range", caIntegrator applies both masks at the same time.
The Data Dictionary page now has a Restrictions column that shows restrictions whenever a mask has been applied.Permissible/Non-permissible Values
Note: The first time you load a file, before you assign annotation definitions, step #3 in #Assigning An Identifier or Annotation, these panels may be blank. If the column header for the data is already "recognizable" by caIntegrator, the system makes a "guess" about the data type and assigns the values to the data type in the newly uploaded file. They will display in the Non-permissible values sections initially. Use the Add and Remove buttons to move the values shown from one list to the other, as appropriate.
...
- Enter search keyword(s) in the Search text box on the Assign Annotation Definition page (the preceding figure). Click Search or click Enter to launch the search. After a few moments, the search results display on the same page. An example of search results is shown in the following figure.
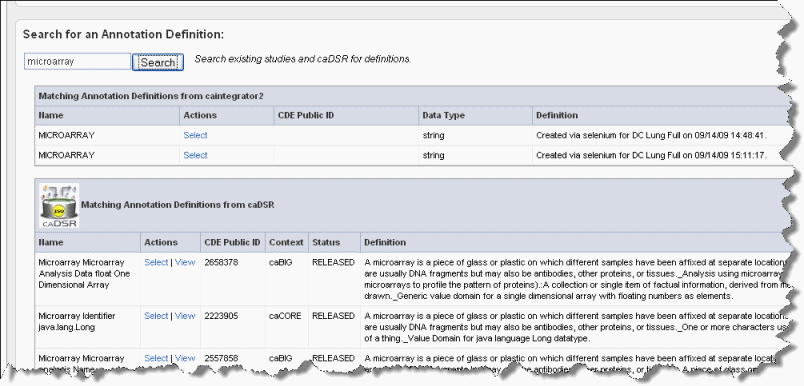
Wiki Markup To view the definitions corresponding to any of the "Matching Annotation Definitions", which are those currently found in other caIntegrator studies, click the \[term\], such as "age", hypertext link. The definition then appears in the Current Annotation Definition segment of the page just above.
Info title In Summary When you click the link for a definition, that assigns the definition to the Define Fields for Subject Data page, and it also closes the Annotation Definition page. You can modify any portion of the definition, as described in Step 6 in #Assigning an Identifier or Annotation.
- The matches from caDSR display some of the details of the search results. To view more details of a match, such as permissible values, click View, which opens caDSR to the term. If you click Select, the caDSR definition automatically replaces the annotation definition for this field with which you are working.
Note title Caution Take care before you add a caDSR definition that it says exactly what you want. caDSR definitions can have minor nuances that require specific and limited applications of their use.
- Once you have settled on an appropriate field definition for the annotation, click Save. This returns you to the Define Fields for Subject Data page.
Info title Note If you have not clicked Select for alternate definitions in this dialog box, then click Save to return to the Define Field...dialog box without making any definition changes.
- From the Define Fields for Subject Data page, be sure and designate the data types for each field in the file. Click Save on each page to save your entries or click New to clear the fields and start again. You will not be able to proceed until every field definition entry on the Fields for Subject Data screen has an entry, one as the unique Identifier and the remainder as annotations.
The Data From File columns on the Define Fields... page display the column header values of the first three rows you designated as "annotations".
The Edit Study page now displays a "Not Loaded" status for the file whose annotations (column headers) you have defined. An example of a file whose annotations have been defined but not yet loaded is shown in the following figure.Tip title Tip Saving your entries in this way saves the study by name and description, but does not deploy the study. See #Deploying the Study.
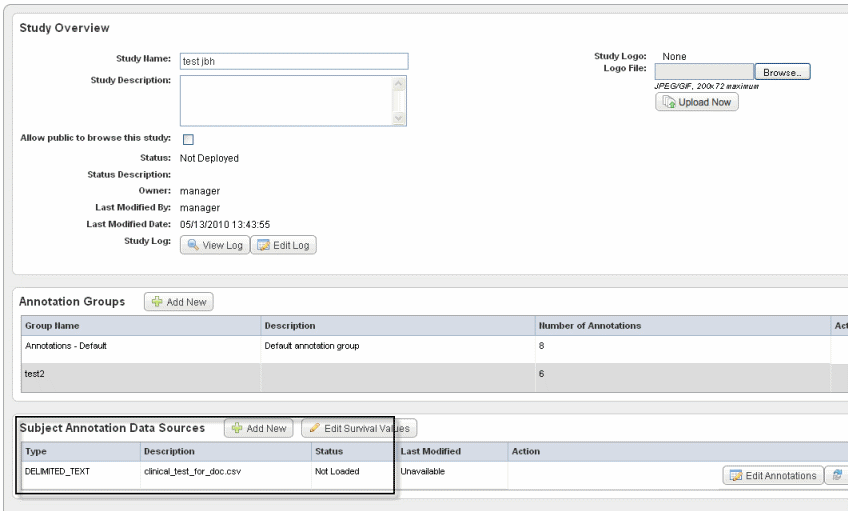
Status definitions:- Definition Incomplete – An annotation definition or definitions must be modified on the Define Fields for Subject Data page. This status may be displayed because an identifier has not been selected. See #Define Fields Page for Editing Annotations.
- Not Loaded – The annotation definitions must be loaded before a study can be deployed. If an error appears after attempting to load a subject annotation source, cick the Edit Annotations button which takes you to the Define Fields for Subject Data page where the problematic annotations will appear in red. See #Define Fields Page for Editing Annotations.
- Loaded – The annotation definitions are properly loaded.
- Click the Load Subject Annotation Source button in the Action section to load the data file you have configured, The Deploy Study button, to this point has been unavailable, but this step activates the button.
Tip title Adding Files You can add as many files as are necessary for a study. Patients 1-20 in first file, 21-40 in second file, or many patients in first file and annotations in second file, etc. As long as IDs are defined correctly, it works.
- Click Deploy Study. caIntegrator now loads data from the file to the caIntegrator database, and the file status changes to "Loaded".
Tip title Changing Assignments You can change assignments even after the study is deployed, using the Edit feature. For more information, see #Creating/Editing a Study.
...
- On the Edit Study page, click Edit Survival Values. This opens the Survival Value Definitions dialog box, shown in the following figure.
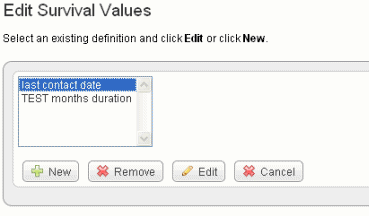
- Click New to enter new survival value definitions.
OR
Click Edit to edit existing survival value definitions.
The dialog box extends, now displaying radio buttons and three drop-down lists that show column headers for date metadata in the spreadsheet you have uploaded. If survival value ranges have already been added to a study, they display on the page. The dialog box is shown in the following figure.
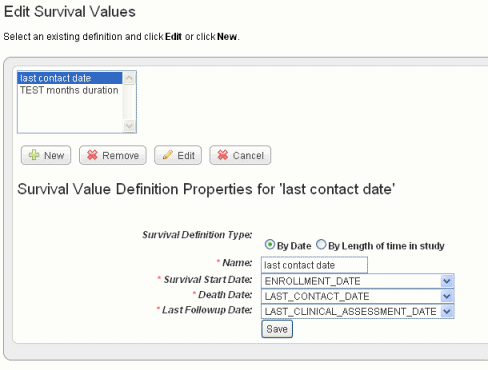
- Survival values can be defined by Date or by Length of time in the study. Select the radio button for the category that defines the data.
- In the drop-down lists, select the appropriate survival value definitions for each field listed. You might want to refer to the column headers in the data file itself. Because dates covered by the definitions are already in the data set, you cannot enter specific dates.
Field Type
Description
Survival Definition Type
Select whether the survival time is defined by dates or length of time subject was in the study.
Name
Enter a unique name that adequately describes the survival values you are defining here. Example: Survival from Enrollment Date or Survival from Treatment Start. The name you enter displays later when you are selecting survivals to create the K-M plot.
Survival Length Units
Select the appropriate units for this data.
Survival Start Date
Select the column header for this data.
Death Date
Select the column header for this data.
Last Followup Date
Select the column header for this data.
...
- On the Edit Study page where you have selected and added the subject annotation data, click the Add New button under Genomic Data Sources. You can upload genomic data only from caArray.
This opens the Edit Genomic Data Source dialog box. Enter the appropriate information in the fields, shown in the following figure and described below.
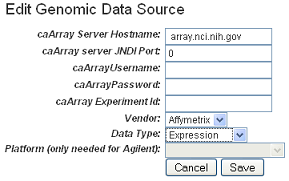
Field Types
Field Description
caArray Web URL
Enter the URL for the caArray instance to be used for the genomic data sources. This will enable a user to link to the referenced caArray experiment from the study summary page.
caArray Host Name
Enter the hostname for your local installation or for the CBIIT installation of caArray. If you misspell it, you will receive an error message.
caArray JNDI Port
Enter the appropriate server port. See your administrator for more information. Example: For the CBIIT installation of caArray, enter 8080.
caArray Username and caArray Password
If the data is private, you must enter your caArray account user name and password; you must have permissions in caArray for the experiment. If the data is public, you can leave these fields blank.
caArray Experiment ID
Enter the caArray Experiment ID which you know corresponds with the subject annotation data you uploaded. Example: Public experiment "beer-00196" on the CBIIT installation of caArray (array.nci.nih.gov). If you misspell your entry, you will receive an error message.
Vendor
Select either Agilent or Affymetrix.
Data Type
Select Expression or Copy Number.
Platform
If appropriate, select the Agilent or Affymetrix platform.
Info title Note Because you can add more than one set of genomic data to a study, a study can also have multiple platforms, one for each set of genomic data.
Central Tendency for Technical Replicates
If more than one hybridization is found for the reporter, the hybridizations will be represented by this method.
Indicate if technical replicates have high statistical variability
If more than one hybridization is found, checking this box will display a ** in the genomic search results when a reporter value has high statistical variability.
Standard Deviation Type
When the checkbox for indicating if technical replicates have high statistical variability is checked, this parameter becomes available. Select in the drop-down the calculation to be used to determine whether or not to display a ** (see previous bullet point).
--Relative calculates the Relative Standard Deviation in percentage value
--Normal calculates the Standard Deviation in numeric valueStandard Deviation Threshold
When the checkbox for indicating if technical replicates have high statistical variability is checked, this parameter becomes available. This is the threshold at which the Standard Deviation Type is exceeded and the reporter is marked with a **.
- Click Save.
caIntegrator goes to caArray, validates the information you have entered here, finds the experiment and retrieves all the sample IDs in the experiment. Once this finishes, the experiment information displays on the caIntegrator Edit Study page under the Genomic Data Sources section, as shown in the following figure. caIntegrator refreshes carray data on an hourly basis. The status of caArray data updates displays on the Manage Studies page and on the Edit Sample Mappings page.

| Info | ||
|---|---|---|
| ||
If you want to redefine the caArray experiment information, you can edit it. Click the Edit link corresponding to the Experiment ID. The Edit Genomic Data Source dialog box reopens, allowing you to edit the information. |
...
- On the Edit Sample Mappings page, shown above, click the Map Samples link.
- Click Browse to navigate for the control samples file, and click the Upload Control Samples File button. The control sets display at the top of the page once they have been uploaded, as shown in the following example.
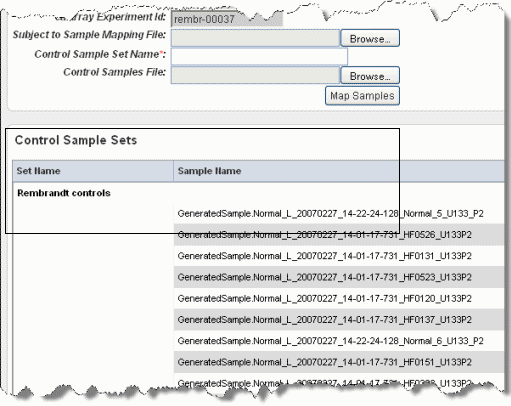
The control samples now display toward the bottom of the page.
...
- In the Genomic Data Sources section of the Edit Study page, for the data you have already added, click Configure Copy Number Data button.
The Edit Copy Number page, shown in the following figure, opens.Info title Note This link is available only if you have uploaded copy number data and you are configuring a Copy Number data type (as indicated by the Data Type column on the Edit Study page).
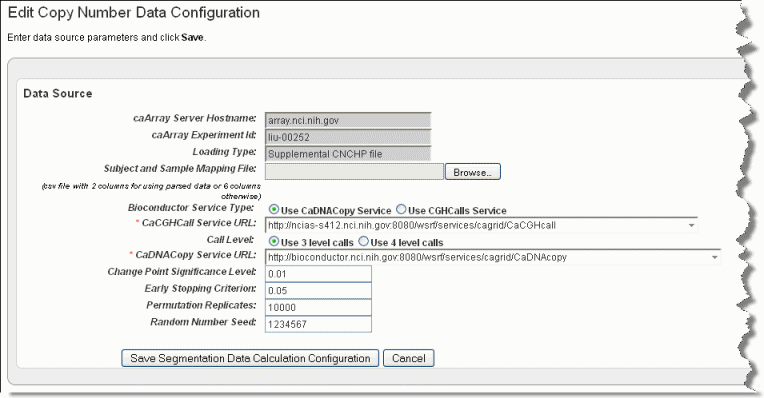
- Browse for and enter appropriate information to identify and retrieve the copy number mapping file. The fields are described in the following table. An asterisk indicates a required field.
Field
Description
caArray Service Host Name
Enter the hostname for your local installation or for the CBIIT installation of caArray. If you misspell it, you will receive an error message.
caArray Experiment ID
Enter the caArray Experiment ID which you know corresponds with the copy number data.
Loading Type
Enter the Loading Type of the data file you plan to map.
Subject and Sample Mapping File
Browse for the appropriate CN mapping file. The file must be a CSV file with 3 column format for mapping data files (format: subject id, sample id, file name). Supplemental data uses 6 column-files.
Bioconductor Service Type
This is the type of bioconductor module that will be used for segmentation. Select between the two options: DNAcopy or CGHcall.
caCGHcall Service URL
Enter the URL for the grid segmentation service used to access the caCGHcall service. For more information, see CGHcall
Call Level
An input parameter to CGHcall. This is the number of discrete values used to represent the copy number level. Select between two options: 3 (consisting of discrete values of -1, 0, 1) or 4 (consisting of discrete values -1, 0, 1, 2)
caDNACopy Service URL
Control for selecting the URL which hosts the caDNACopy grid service. For more information, see DNAcopy
.
Change Point Significance Level
Significance levels for the test to accept change-points
Early Stopping Criterion
The sequential boundary used to stop and declare a change
Permutation Replicates
The number of permutations used for p-value computation
Random Number Seed
The segmentation procedure uses a permutation reference distribution. This should be used if you plan to reproduce the results.
- Click Save Segmentation Data Calculation Configuration for a genomic data source. On the screen upload a copy number mapping file and configure the parameters to be sent when computing segmentation data.
Note title Be Careful After a study has been deployed and the genomic source has been loaded, you cannot change these copy number parameters without reloading the data from caArray first.
...
- On the Edit Study page under the Imaging Data Sources section, click the Add New button.
Info title Note If you have already provided an imaging data source, it is listed in this section of the Edit Study page. To edit the imaging data source, click the Edit button which opens the same dialog box described in the following steps.
- In the Edit Imaging Data Source dialog box, configure the appropriate imaging data source information in the fields as shown in the selected area of the following figure and described below. Fields with an asterisk are required.
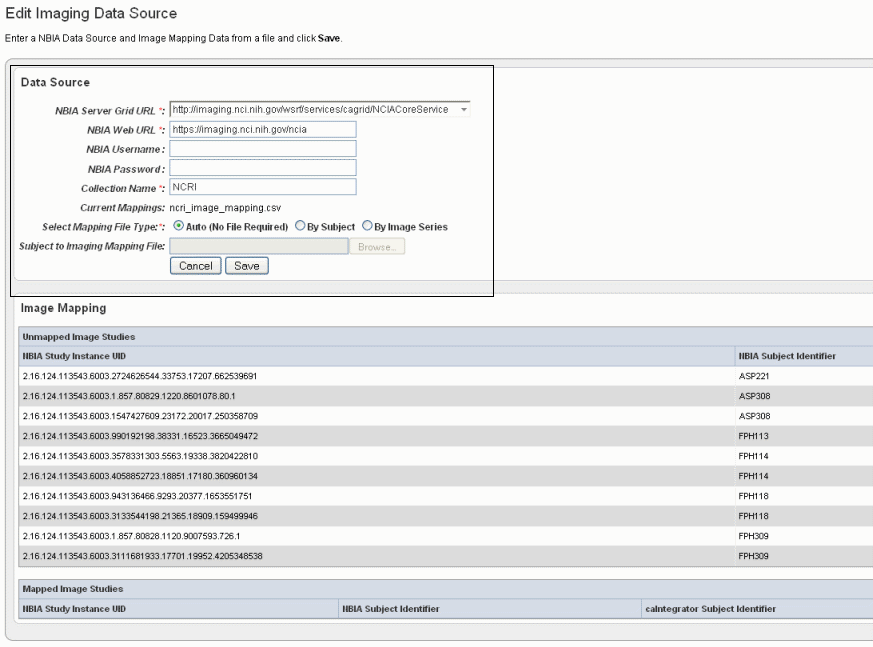
Fields
Description
NBIA Server Grid URL*
Enter the URL for the grid connection to NBIA.
NBIA Web URL
Enter the URL of the web interface of the NBIA installation.
NBIA Username and NBIA Password
This information is not required, as currently all data in the NBIA grid is Public data.
Collection Name
Enter the name/source for the collection you want to retrieve.
Current Mapping
If a mapping file has already been uploaded to the study to map imaging data, the file name displays here.
Select Mapping File Type
Click to select the file type:
--Auto – No file is required. Selecting this takes all subject annotation subject IDs and attempts to map them to the corresponding ID in the collection in NBIA. If the ID does not exist in NBIA, then no mapping is made for that ID.
--By Subject – Requires a mapping file to be uploaded. The "subject annotation to imaging mapping file" must be in CSV format with two columns that map the caIntegrator subject annotation subject ID to the NBIA subject ID.
--By Image Series – Requires a file to be uploaded. The subject annotation to imaging mapping file needs to be a two column mapping (CSV) from the caIntegrator subject annotation subject ID to the NBIA study instance UID.Subject to Imaging Mapping File
Click Browse to navigate to the appropriate subject annotation to imaging mapping file. See the Select Mapping File Type* field description.
Info title Note If mapping files have already been uploaded for the data sources you are editing, the Image Mapping tables of the dialog box show the mapping from NBIA Image Series Identifier to caIntegrator Subject Identifier.
- Click Save to upload the data from NBIA to caIntegrator. The imaging data displays on the Edit Study page under the Imaging Data Sources section, as shown in the following figure.

- Once the data is uploaded, you can add image annotations. For more information, see #Adding or Editing Image Annotations.
...
- On the Edit Study page, click the Edit Annotations button under the Image Data Sources section.
Info title Note If you have not yet imported annotations, clicking this button opens the page from which you can import image annotations, shown in the following figure. Continue with the steps in this section. If you are editing annotations, clicking this button opens the Define Fields for Image Annotations dialog box where you can edit annotations; see #Define Fields Page for Editing Annotations.
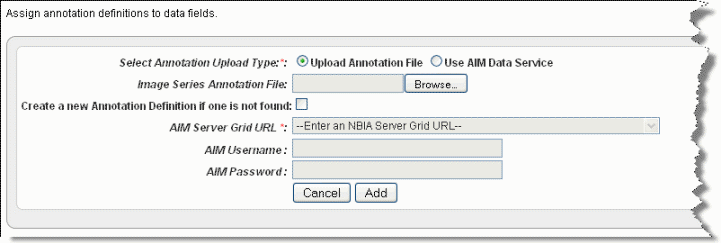
- Select the radio button Upload Annotation File.
- Click Browse to select an annotation CSV file for upload.
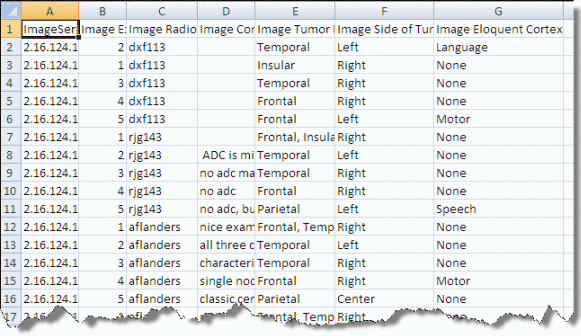
Info title Note An image annotation CSV file must include an Image Series ID column. See the highlighted column in the following figure.
- Check the box for Create a new Annotation Definition if one is not found (if appropriate).
- Click Add.
...
Once you have created external links for a study, when the study is open, an External Links section on the left sidebar of the page shows the link(s). An example is identified in the following figure.
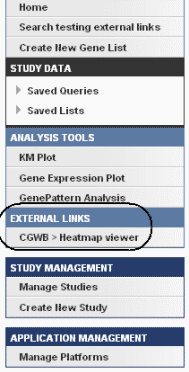
Click an external link to open a page that displays appropriately formatted web page links; an example is shown in the following figure.

Deploying the Study
...