"
Author: Traci St.Martin/Craig Stancl
Email: stancl.craig@mayo.edu
Team: LexEVS
Contract: [Contract number]
Client: NCI CBIIT
National Institutes of Heath
US Department of Health and Human Services
Sign off |
Date |
Role |
CBIIT or Stakeholder Organization |
Reviewer's Comments (If disapproved indicate specific areas for improvement.) |
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Design Review Comments
Reviewer |
Date |
Comment/ Question |
Suggestions / Discussion |
Resolution |
|---|---|---|---|---|
RAH |
5-Apr |
Under High level Architecture - CTS 2 Query Profile |
Reword to: |
Agree. |
RAH |
5-Apr |
Under High level Architecture - Terminology Administration |
Reword to: |
Leave current wording, but include "Control Content Access" |
RAH |
5-Apr |
Under High level Architecture - Terminology Authoring |
Move to CTS 2 Query profile, and add "terminology content maintenance" bullet under Authoring Profile. |
The SFM does call this out in section 7.2.3. Change to "functional terminology analysis/query" |
RAH |
5-Apr |
Semantic Profiles - HL7 Profile |
Include bullets for:
|
For example, datatypes are more structural and less functional. |
RAH |
5-APR |
High Level Design Diagram |
For discussion: |
Both CTS 2 APIs and caCORE APIs can indeed be used simultaneously. |
RAH |
5-APR |
In Functional Profiles: |
|
Yes, it is included. |
RAH |
5-APR |
In Functional Profiles: |
|
Yes, thought given. Yes, the will be supported. This should be included in design doc. |
RAH |
5-APR |
Levels of mapping: |
|
Nothing to do here. |
RAH |
5-APR |
CTS 2 Specific Pick List Services: |
While this is technically correct in that CTS 2 does not call out specific functional requirements for pick lists. |
LexEVS has better coverage than what is defined in SFM. |
RAH |
5-APR |
CTS 2 Authoring Profile states:
|
WARNING: THE RIM DB no longer supports the full content of value sets and code systems used by HL7. |
Comment noted. |
The purpose of this document is to collect, analyze, and define high-level needs for and designed features of the [Product or Component Name x.x].
The focus is on the functionalities proposed by the stakeholders and target users to make a better product.
The use case documents show in detail how the features meet these needs.
Note
Use the sub-headings that you need for details of your Design Scope, Solution Architecture, and Implementation Requirements. Delete the ones you do not need, along with this note.
Design Scope
text for design scope here
High Level Architecture
Structure of the CTS 2 Service
The functional CTS 2 Model defines several functional profiles. These profiles are a focused subset of the functionality of a CTS 2 implementation.
CTS 2 Query Profile:
- Searching and querying terminologies
- Provide access to terminology content and representational structures (description logic) consistent with the terminology author's intent.
Terminology Administration Profile:
- Restricting administrative access
- Obtaining and loading terminologies
- Maintaining terminology access
- Control Content Access
Terminology Authoring Profile:
- functional terminology analysis/query
- direct terminology edits

Semantic Profiles
HL7 Profile:
- Functional coverage and specificity necessary for HL7 conformance
- Searching terminology content
- Interchange content in the the Model Interchange Format.
- Use of HL7 Datatypes
- (Model Interchange Format (MIF) Representation of terminology content
Mature Terminology Profile:
- Best practices conformance for the terminology
Developing Terminology Profile:
- ad hoc or degraded terminologies
High Level Design Diagram

CTS 2 Functional Profiles
CTS 2 Query Profile
List Code Systems |
The ability to provide a listing of the available code |
Return Code System Details |
The ability to retrieve a specific code system attributes |
List Code System Concepts |
The ability to retrieve a list of all of the concepts, |
Return Concept Details |
The ability to retrieve a specific concept, with |
List Value Sets |
The ability to determine what value sets are available to |
Return Value Set Details |
The ability to retrieve a specific value set, with |
List Value Set Contents |
The ability to see a listing of specific concepts, as well |
Check Concept Value Set Membership |
The ability to validate that a given concept exists in a |
List Concept Domains |
The ability to determine what concept domains are |
Return Concept Domain Details |
The ability to retrieve a specific concept domain, with |
List Concept Domain Bindings |
The ability to see a listing of specific value sets that |
Check Concept Domain Membership |
The ability to validate that a given concept code is bound |
List Usage Contexts |
The ability to determine what usage contexts are available |
Return Usage Context Details |
The ability to retrieve a specific usage context, with |
List Associations |
The ability to determine what associations are available |
Return Association Details |
The ability to retrieve metadata on available associations |
List Association Types |
Returns the details for the known attributes (metadata) of |
Return Association Type Details |
The ability to return all information for a Association |
Check Value Set Subsumption |
Determine whether one of the two supplied value sets |
Check Concept to Concept Domain Association |
Determine whether the supplied coded concept exists in a |
Determine Transitive Concept Relationship |
Determine whether there exists a transitive relationship between two |
Compute Subsumption Relationship |
Determine Whether One Concept Subsumes a Second |
Terminology Administration Profile
Import Code System |
Terminology content would be loaded into the terminology |
Import Code System Revision |
Terminology content would be loaded into the terminology |
Import Value Set Version |
Ability to import values sets |
Import Association version |
Ability to import Associations |
Export Association |
Ability to export Association Type instances |
Export Code System Content |
Terminology content would be exported either in whole or |
Change Code System Status |
Terminology content status would be changed, thus changing |
Register for Notification |
A client registers for notification so that an electronic |
Update Notification Registration |
Subscription notification information can be updated for a |
Update Notification Registration Status |
Updates the status of a notification registration. |
Terminology Authoring Profile
Create Code System |
The ability to create a new Code System to contain a set |
Maintain Code System Version |
The ability to maintain the content and metadata of a |
Update Code System Version Status |
The ability to modify the status of a code system. |
Create Concept |
The ability to define and add a new concept to a code |
Maintain Concept |
The ability to modify a concept that exists in a code |
Update Concept Status |
The ability to modify the status of a concept that exists |
Create Value Set |
The ability to create a dynamic value set that is defined |
Maintain Value Set |
Update properties or expression of a value set definition |
|
|
Update Value Set Status |
The ability to modify the status of a value set. |
Create Concept Domain |
The ability to define and add a new concept domain. |
Maintain Concept Domain |
The ability to modify a concept domain, including bindings |
Create Usage Context |
The ability to define and add a new usage context. |
Maintain Usage Context |
The ability to modify a usage context. |
Terminology Administration Profile |
The Terminology Administration profile is intended to |
Create Association |
The ability to create an association between concepts. |
Update Association Status |
The ability to update the status of an association between |
Create Association Type |
The ability to create a new Association type that may be |
Maintain Association Type |
The ability to modify or deprecate an existing Association |
Create Lexical Association Between Coded Concepts |
The ability to instantiate an association between two sets |
Create Rules Based Association Between Coded Concepts |
The ability to instantiate an association between two sets |
Create Code System Supplement |
Create a new Code System Supplement as a container of a |
Maintain Code System Supplement |
Update Code System Supplement meta-data properties and add |
A Sub Categorization of Services
CTS Services can be further categorized from the profile details above:

CTS Service Interfaces
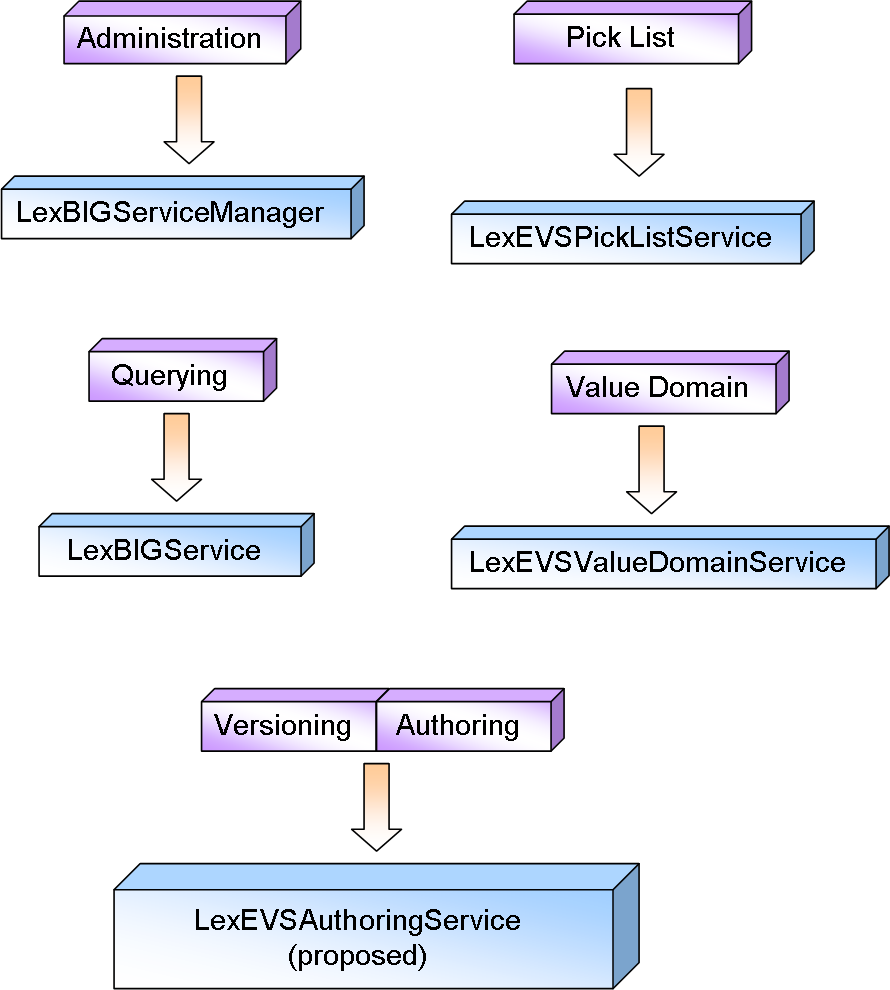
GForge items
One heading for each item, to include functional and non-functional requirements and bug fixes.
Use cases
Links to available documents.
Related requirements
One heading for each item.
Solutions Architecture: XML Loads of LexGrid Modeled Content
Overview:
Loads of LexGrid XML were formerly limited by the size of the Coding Scheme model element that could be constructed in memory.
Loaded models had a single entry point at the CodingScheme element. With the intention of providing improved loading performance,
access points to other levels of LexGrid Model elements, and a convenient format for authoring, the design of the 5.1 XML Loader has been
updated for LexEVS 6.0 and will be implemented with the following considerations:
- A streaming implementation of the loading mechanism allowing larger loads in a smaller memory footprint.
- A variety of entry points to facilitate loading of Revisions, System Releases, Value Sets, Pick Lists, and Coding Schemes.
- A loading mechanism for Authoring based manipulation of LexGrid based xml files allowing entities and associations to be added
to a given coding scheme in XML, then loaded into a LexGrid data repository.
Streaming XML Implementation
The latest implementation of the LexGrid XML loader provides a partitioned load of a coding scheme or other potentially large elements.
The 6.0 loader will read coding scheme meta data into memory, load it to the LexGrid database and then begin stepping through entities and associations
persisting elements to the database and then removing them from the coding scheme object as the unmarshaller reads objects from XML and into the coding scheme
object in memory. Streaming XML reads while controlling the build of the coding scheme (and potentially other objects) in memory allowing the load of
far larger terminologies constructed in LexGrid xml. This also allows users to eventually export larger coding schemes, revise them with authoring tools,
and reload them as LexGrid Revision elements. This and other authoring scenarios will be exercised upon LexGrid XML with subsequent loads to the
LexGrid database possible. (See authoring design below.)
LexGrid coding scheme meta data contains an number of required and optional elements as defined in the LexGrid schema. The last of these elements, before entity and associations
are expressed, are the coding scheme mappings and the coding scheme properties. Mappings are required elements in the coding scheme and as
such are a default stopping point of coding scheme reads. Coding scheme properties are not required and as such may not exist in a given rendering of LexGrid XML.
Before persistence of meta data to the LexGrid database takes place, a high speed pass is made over the coding scheme meta data portion of the XML with the STAX
parser api to determine coding scheme properties presence.
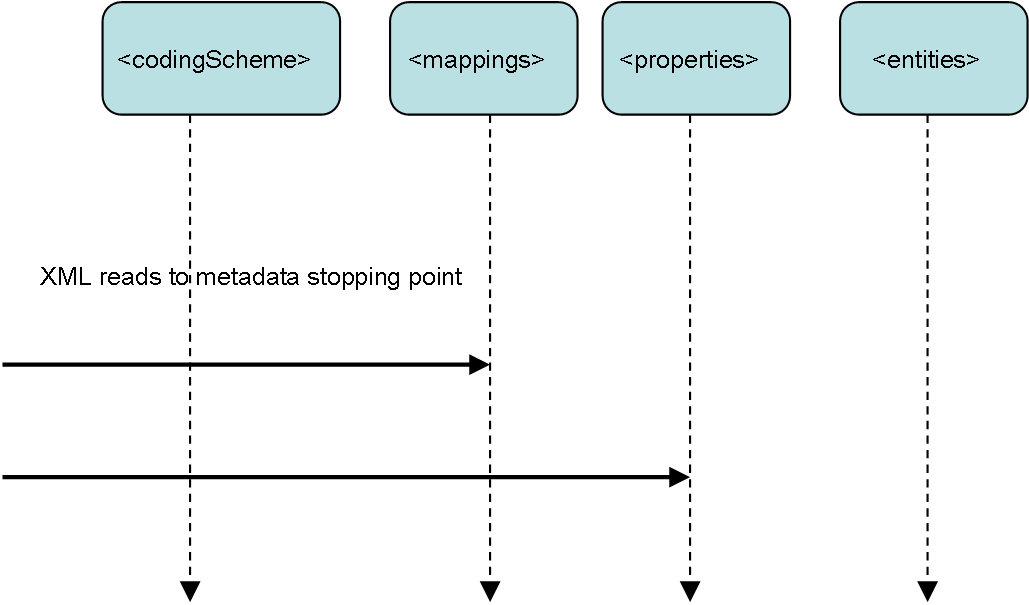
The bulk of the coding scheme elements are read, stored to database, and de-referenced to allow sufficient memory management.
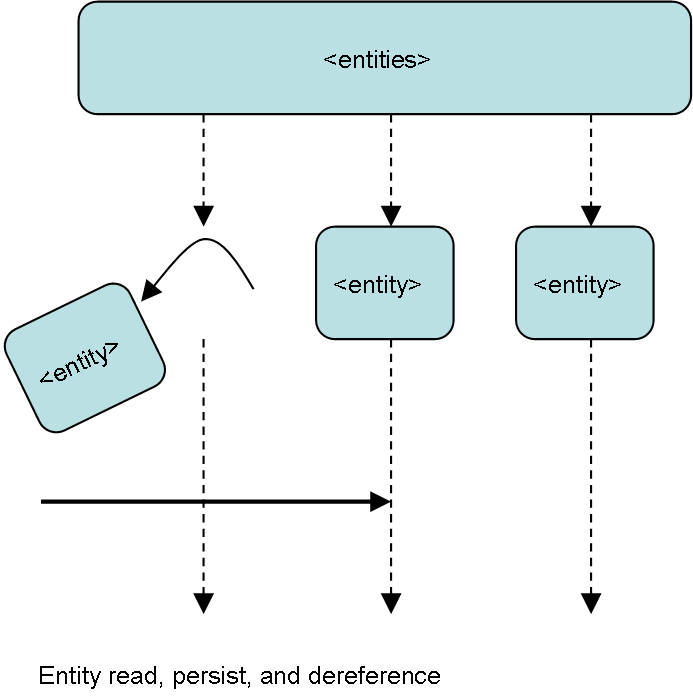

Entry Points Expanded
Coding Scheme Entry Point
Previously, coding scheme was the only entry point for persisting loading to the LexGrid data base. Since pick lists, value domains, and revisions
required more flexibility in XML based loads, entry points for revisions and system releases were also added.

Revision Entry Point
Revisions can be applied to Coding Schemes, Pick Lists and Value Sets. A single revision element can load a set of revisions of coding schemes, pick lists and value sets.

Revision can contain a variety of changed elements.

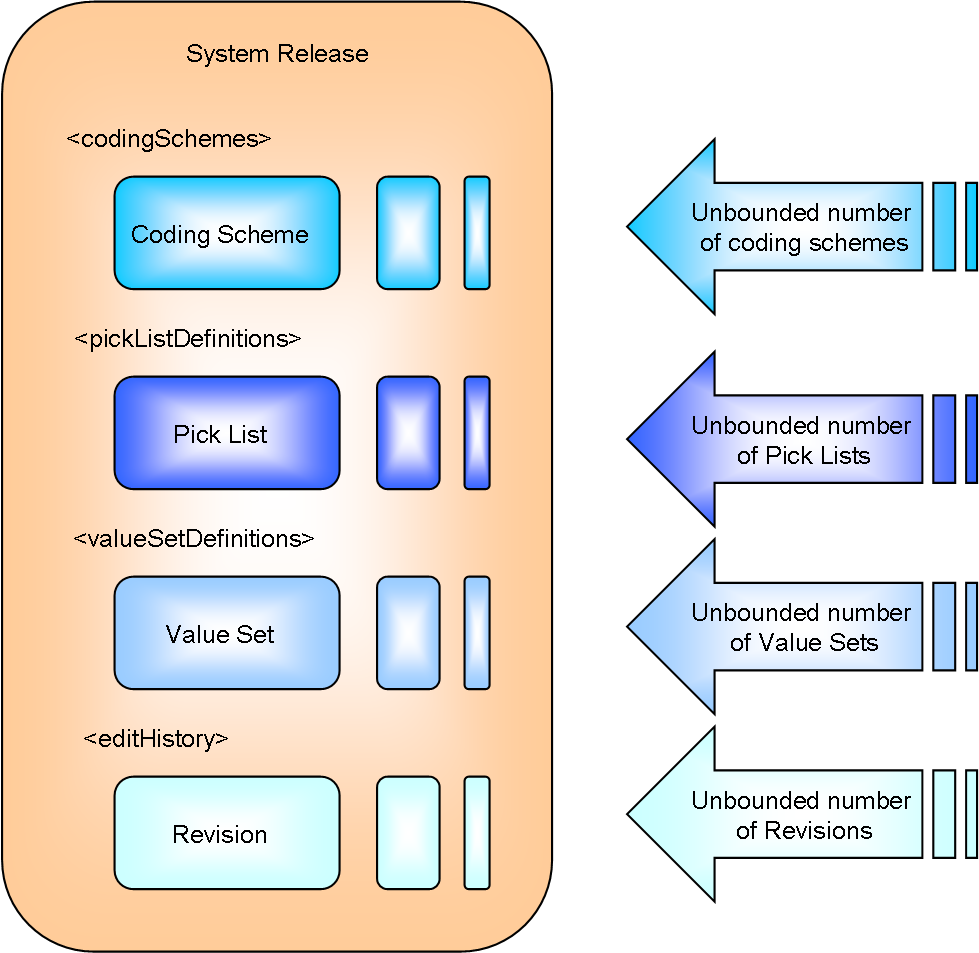
System Release Entry Point
System Release is primarily intended as a release point for collections of pick lists and value sets. It is beyond
the scope of this implementation to load multiple coding schemes contained within a system release. The technical
problems implied by the loads of a System Release containing multiple large coding schemes suggests that such a use case
is impractical in many scenarios.
Solutions Architecture: Associations and Mapping
Placeholder for mapping designs

Levels of Mapping Implementation implied by current requirements from various stakeholders
There are multiple levels at which mapping, as evaluated here, could be considered to be "supported":
- The ability to store map sets, look up map sets by id, from, to
and other attributes and to look up entries by source, target and/or
relationship. We would have to store all of the additional information
such as options, rules, categories, advice, etc, but it would be up to
external software to interpret and evaluate the contents. - Everything in option 1) above plus the ability to query
additional fields - give me an ordered, structured list of a mapping
entry in a way that someone could write a standard interpreter to
evaluate it - this would basically require the addition of a model and
would most likely cause us to split from the existing relations model,
as it gets into the domain of table driven rule sets. - Everything in 1) and, possibly 2) with the added ability to
actually interpret the rules - an API that answers questions such as
"What information is needed to map 231754000 (poisoning by sodium
valproate) correctly?" (answer - whether barbituates, sulfonamides were
present, whether combined with various substances, etc). "What does
231754000 in the presence of ... map to?
Evaluation of Levels of Mapping Implementation for CTS 2
For LexEVS 6.0 (CTS 2), (3) is out of scope. This is
the function of a rules engine and the complexities of even the supplied
examples are overwhelming. We may want to examine the DSS RFP to see
whether there is anything there that applies. It appears that (2)
is out of scope as well, as, whether we interpret the semantics of the
rules or not, the structure required to represent the rules still lies
well within the rule base and DSS space. The question is, then, whether
item (1) adds sufficient value to be worth doing. My take is "no" as
well, as trying to fit all of the various aspects of the mapping rules
that we've seen to date into the nooks and crannies of the LexGrid
mapping model seems to be an exercise with little return.
What we need to do is to return to the set of use cases, if any,
that LexEVS could reasonably resolve. As there are simpler use
cases, such as those presented by various stakeholders, we will clearly need to
resolve them and, if it would be useful, could answer the same questions
for complex mappings. Once, however, we get to the point of
determining what participates in a particular map, it seems like we are
getting out of our scope - the best we might do is supply the
associationId that could be used as an index into another table.
Proposed Solution
Model Changes

The relations attribute in the model will have the following elements and attributes added:
- representsVersion - if present, the source asserted version of the collection of relations or mappings
- isMapping - if true, this collection of relations represents a mapping and will be evaluated for "mapping" related queries.
- sourceCodingScheme - if present, the local identifier of the namespace that the sourcEntityCodes are derived from.
- sourceCodingSchemeVersion - the source asserted version identifier of the source coding scheme. If present, this becomes the default for sourceEntityCodeNamespace.
- targetCodingScheme - if present, the local identifier of the namespace that the targetEntityCodes are derived from. If present, this becomes the default for targetEntityCodeNamespace.
- targetCodingSchemeVersion - the source asserted version identifier of the target coding scheme
- properties - all other properties on the "relations bucket" level that don't fit one of the items in the Relations container
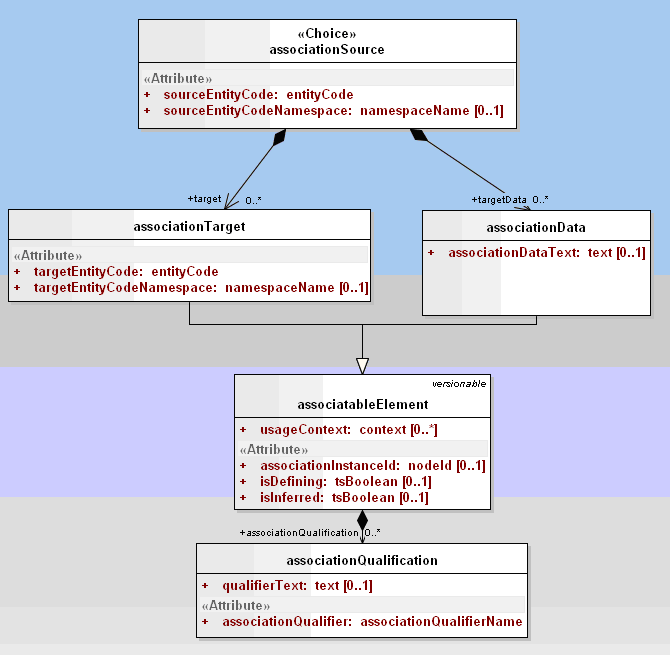
There are no additional changes for the second part of the model, shown above.
Content Representation
MRSAT Mappings
MRSAT Column |
Function |
LexGrid Equivalent |
MAPSETVERSION |
|
Relations.representsVersion |
FROMVSAB |
The from code system version |
Relations.fromCodingSchemeVersion |
FROMRSAB |
The from code system |
Relations.FromCodingScheme |
TOVSAB |
The to code system version |
Relations.toCodingSchemeVersion |
TORSAB |
The to code system |
Relations.toCodingScheme |
MAPSETRSAB |
Source of the value set |
Relations.owner |
(anything else) |
|
Relations.property[key] |
MRMAP Mappings |
There are at least two possibilities for the MRMAP transformations into LexGrid. The first, the "flattened transformation" puts the entire MRMAP row into the table:
MRMAP Flattened Option
MRMAP Column |
Function |
LexGrid Equivalent |
MAPSETCUI |
|
Relations.containerName |
MAPID |
Row identifier |
Target.associationInstanceId |
FROMEXPR |
Source code or expression |
Source.sourceEntityCode |
REL |
UMLS asserted relationship |
associationPredicate (if RELA absent) |
RELA |
Source asserted relationship |
associationPredicate(if not blank) |
TOEXPR |
Target code or expression |
Target.targetEntityCode (if code) |
TOTYPE |
Type of the data |
targetData.associationDataText.dataType (if target is not code) |
(entire MRMAP row |
|
Target(Data).associationQualification[MRMAP entry] |
MRMAP Expanded Option |
MRMAP Column |
Function |
LexGrid Equivalent |
MAPSETCUI |
|
Relations.containerName |
MAPID |
Row identifier |
Target.associationInstanceId |
FROMEXPR |
Source code or expression |
Source.sourceEntityCode |
REL |
UMLS asserted relationship |
associationPredicate (if RELA absent) |
RELA |
Source asserted relationship |
associationPredicate(if not blank) |
TOEXPR |
Target code or expression |
Target.targetEntityCode (if code) |
TOTYPE |
Type of the data |
targetData.associationDataText.dataType (if target is not code) |
(anything else) |
|
Target(Data).associationQualification[associationQualifier] |
Expression Issues
One of the requirements for mapping has been the ability to discover what maps a given entity (may) participate in.
This will not be completely answerable in situations where the codes are carried in text expressions. One alternative
would be to parse the target expression when possible and to create multiple rows, one for each target. Besides the parsing
complexity, however, the other issue is that it is not possible to record the expression operators (AND, OR, ...)
in the expansion. This, however, would arguably be the best use of the mappings for this level of complexity.
Sample Mapping XML
<?xml version="1.0" encoding="UTF-8" ?>
- <codingScheme xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://LexGrid.org/schema/2010/01/LexGrid/codingSchemes file:/C:/devel/v6/lexgrid_model/lgModel/master/relations.xsd" xmlns="http://LexGrid.org/schema/2010/01/LexGrid/codingSchemes" xmlns:lgBuiltin="http://LexGrid.org/schema/2010/01/LexGrid/builtins" xmlns:lgCS="http://LexGrid.org/schema/2010/01/LexGrid/codingSchemes" xmlns:lgCon="http://LexGrid.org/schema/2010/01/LexGrid/concepts" xmlns:lgCommon="http://LexGrid.org/schema/2010/01/LexGrid/commonTypes" codingSchemeName="UMLS" codingSchemeURI="urn:oid:2.16.840.1.113883.6.2" representsVersion="http://SharedNames.org/ontology/umls/2009AB">
<mappings />
- <!-- MRSAT entry
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT115321814||MAPSETVERSION|MTH|2010_2009_08_17|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT115321815||TOVSAB|MTH|MSH2010_2009_08_17|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT37361323||FROMRSAB|MTH|MTH|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT37361327||FROMVSAB|MTH|MTH|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT37361343||MAPSETGRAMMAR|MTH|ATX ::= expr; expr ::= disj; disj ::= conj , conj "OR" conj; conj ::= unary , unary "AND" unary; unary ::= neg , pos; neg ::= "NOT" pos; pos ::= "(" expr ")" , slash , atom; slash ::= atom , atom "/" atom; atom ::= "<" (any non ">" character) ">";|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT37361355||MAPSETRSAB|MTH|MTH|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT37361364||MAPSETTYPE|MTH|ATX|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT37361368||MAPSETVSAB|MTH|MTH|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT37408395||TORSAB|MTH|MSH|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT37424062||SOS|MTH|This map set contains mappings from Metathesaurus CUIs to MSH associated expressions.|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT56870375||MTH_MAPFROMEXHAUSTIVE|MTH|N|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT56870378||MTH_MAPSETCOMPLEXITY|MTH|ONE_TO_ONE|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT56870384||MTH_MAPTOEXHAUSTIVE|MTH|N|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT65576316||MTH_MAPFROMCOMPLEXITY|MTH|SINGLE CUI|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT65576317||MTH_MAPTOCOMPLEXITY|MTH|BOOLEAN_EXPRESSION STR|N||
C1306694|L8923988|S11111536|A17029750|CODE|1000|AT67813929||MAPSETSID|MTH|1000|N||
C1306694||||CUI||AT116199817||MR|MTH|20090921|N||
C1306694||||CUI||AT31823722||DA|MTH|20040415|N||
C1306694||||CUI||AT31952620||ST|MTH|R|N||
-->
- <!-- OPTION 1: Everything flattened
-->
- <lgCS:relations containerName="C1306694" isMapping="true" sourceCodingScheme="MTH" sourceCodingSchemeVersion="MTH" targetCodingScheme="MSH" targetCodingSchemeVersion="MSH2010_2009_08_17" representsVersion="2010_2009_08_17" xmlns="http://LexGrid.org/schema/2010/01/LexGrid/relations">
- <!-- This should be MAPSETNAME but, curiously, it is missing from the MRSAT list. We are assuming that "SOS" is the equivalent
-->
<lgCommon:entityDescription>This map set contains mappings from Metathesaurus CUIs to MSH associated expressions.</lgCommon:entityDescription>
- <properties>
- <lgCommon:property propertyName="MAPSETGRAMMER">
<lgCommon:value>ATX ::= expr; expr ::= disj; disj ::= conj , conj "OR" conj; conj ::= unary , unary "AND" unary; unary ::= neg , pos; neg ::= "NOT" pos; pos ::= "(" expr ")" , slash , atom; slash ::= atom , atom "/" atom; atom ::= ">" (any non ">" character) ">";</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MAPSETRSAB">
<lgCommon:value>MTH</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MAPSETTYPE">
<lgCommon:value>ATX</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MAPSETVSAB">
<lgCommon:value>MTH</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPFROMEXHAUSTIVE">
<lgCommon:value>MTH</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPSETCOMPLEXITY">
<lgCommon:value>MTH</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPTOEXHAUSTIVE">
<lgCommon:value>MTH</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPFROMCOMPLEXITY">
<lgCommon:value>MTH</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPTOCOMPLEXITY">
<lgCommon:value>MTH</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MR">
<lgCommon:value>20090921</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="DA">
<lgCommon:value>20040415</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="ST">
<lgCommon:value>R</lgCommon:value>
</lgCommon:property>
</properties>
- <!-- MAPSETCUI|MAPSAB|MAPSUBSETID|MAPRANK|MAPID |MAPSID|FROMID |FROMSID|FROMEXPR|FROMTYPE|FROMRULE|FROMRES|REL|RELA
C1306694 |MTH | | |AT102971857| |C0264643| |C0264643|CUI | | |SY |
|TOID|TOSID|TOEXPR |TOTYPE |TORULE|TORES|MAPRULE|MAPRES|MAPTYPE|MAPATN|MAPATV
|3026| |<Hypertension, Renovascular> AND <Hypertension, Malignant>|BOOLEAN_EXPRESSION_STR| | | | |ATX | | ||
-->
- <associationPredicate associationName="SY">
- <!-- MRMAP Option 1 - Expand each non-semantic MRMAP entry
-->
- <source sourceEntityCode="C0264643">
- <targetData associationInstanceId="AT102971857">
- <associationQualification associationQualifier="FROMTYPE">
<qualifierText>CUI</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="FROMID">
<qualifierText>C0264643</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="TOTYPE">
<qualifierText>BOOLEAN_EXPRESSION_STR</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="TOID">
<qualifierText>3026</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="MAPTYPE">
<qualifierText>ATX</qualifierText>
</associationQualification>
<associationDataText dataType="BOOLEAN_EXPRESSION_STR">>Hypertension, Renovascular> AND >Hypertension, Malignant></associationDataText>
</targetData>
</source>
- <!-- MRMAP Option 2 - Keep MRMAP entry as it is
-->
- <source sourceEntityCode="C0264643">
- <targetData associationInstanceId="AT102971857">
- <associationQualification associationQualifier="MRMAP Entry">
<qualifierText>C1306694|MTH|||AT102971857||C0264643||C0264643|CUI|||SY||3026||>Hypertension, Renovascular> AND >Hypertension, Malignant>|BOOLEAN_EXPRESSION_STR|||||ATX||||</qualifierText>
</associationQualification>
<associationDataText dataType="BOOLEAN_EXPRESSION_STR">>Hypertension, Renovascular> AND >Hypertension, Malignant></associationDataText>
</targetData>
</source>
- <!-- TARGET Option 2 - Semantic interpretation of the target entry
-->
- <!-- NOTE That this loses the operators, but (assuming that the target entries were codes), would maintain the participation
-->
- <source sourceEntityCode="C0264643">
- <target targetEntityCode="Hyptertension, Renovascular" associationInstanceId="AT102971857.1">
- <associationQualification associationQualifier="MRMAP Entry">
<qualifierText>C1306694|MTH|||AT102971857||C0264643||C0264643|CUI|||SY||3026||>Hypertension, Renovascular> AND >Hypertension, Malignant>|BOOLEAN_EXPRESSION_STR|||||ATX||||</qualifierText>
</associationQualification>
</target>
- <target targetEntityCode="Hypertension, Malignant" associationInstanceId="AT102971857.2">
- <associationQualification associationQualifier="MRMAP Entry">
<qualifierText>C1306694|MTH|||AT102971857||C0264643||C0264643|CUI|||SY||3026||>Hypertension, Renovascular> AND >Hypertension, Malignant>|BOOLEAN_EXPRESSION_STR|||||ATX||||</qualifierText>
</associationQualification>
</target>
</source>
</associationPredicate>
</lgCS:relations>
- <!--
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT110721471||FROMVSAB|MDR|MDR12_0|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT110721473||MAPSETVERSION|MDR|200903|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT110721475||MAPSETVSAB|MDR|MDR12_0|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT90562335||FROMRSAB|MDR|MDR|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT90562339||MAPSETRSAB|MDR|MDR|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT90562341||MAPSETTYPE|MDR|MedDRA to ICD9CM Mappings|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT90580448||MTH_MAPFROMCOMPLEXITY|MDR|SINGLE CODE|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT90580450||MTH_MAPFROMEXHAUSTIVE|MDR|N|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT90580452||MTH_MAPSETCOMPLEXITY|MDR|ONE_TO_ONE|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT90580454||MTH_MAPTOCOMPLEXITY|MDR|SINGLE CODE|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT90580456||MTH_MAPTOEXHAUSTIVE|MDR|N|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT91157709||TORSAB|MDR|ICD9CM|N||
C2242749|L8609359|S10707041|A16492852|CODE|MTHU000002|AT91157711||TOVSAB|MDR|ICD9CM_1998|N||
C2242749||||CUI||AT101551784||DA|MTH|20081103|N||
C2242749||||CUI||AT102850765||ST|MTH|R|N||
C2242749||||CUI||AT116202416||MR|MTH|20090926|N||
-->
- <!-- Should this be the code or "MTHU000002"?
-->
- <lgCS:relations containerName="C2242749" sourceCodingScheme="MDR" sourceCodingSchemeVersion="MDR12_0" targetCodingScheme="ICD9CM" targetCodingSchemeVersion="ICD9CM_1998" representsVersion="200903" xmlns="http://LexGrid.org/schema/2010/01/LexGrid/relations">
<lgCommon:owner>MDR</lgCommon:owner>
- <!-- This should be MAPSETNAME but, curiously, it is missing from the MRSAT list
-->
<lgCommon:entityDescription>This map set contains mappings from Metathesaurus CUIs to MSH associated expressions.</lgCommon:entityDescription>
- <properties>
- <lgCommon:property propertyName="MAPSETTYPE">
<lgCommon:value>MedDRA to ICD9CM Mappings</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPFROMCOMPLEXITY">
<lgCommon:value>SINGLE CODE</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPFROMEXHAUSTIVE">
<lgCommon:value>N</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPSETCOMPLEXITY">
<lgCommon:value>ONE_TO_ONE</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPTOCOMPLEXITY">
<lgCommon:value>SINGLE CODE</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPTOEXHAUSTIVE">
<lgCommon:value>MedDRA to ICD9CM Mappings</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MAPSETTYPE">
<lgCommon:value>N</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="DA">
<lgCommon:value>20081103</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="ST">
<lgCommon:value>R</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MR">
<lgCommon:value>20090926</lgCommon:value>
</lgCommon:property>
</properties>
- <!-- MAPSETCUI|MAPSAB|MAPSUBSETID|MAPRANK|MAPID |MAPSID|FROMID |FROMSID|FROMEXPR|FROMTYPE|FROMRULE|FROMRES|REL|RELA
C2242749 |MDR | | |AT91157713 | |10032725| |10032725|CODE | | |RQ |mapped_to
|TOID |TOSID|TOEXPR |TOTYPE |TORULE|TORES|MAPRULE|MAPRES|MAPTYPE|MAPATN|MAPATV
|728.7| |728.7 |CODE |||||||||
-->
- <associationPredicate associationName="mapped_to">
- <!-- Note that "RQ" gets lost in this approach...
-->
- <source sourceEntityCode="10032725">
- <target targetEntityCode="728.7" associationInstanceId="AT91157713">
- <associationQualification associationQualifier="FROMTYPE">
<qualifierText>CODE</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="FROMID">
<qualifierText>10032725</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="TOID">
<qualifierText>728.7</qualifierText>
</associationQualification>
</target>
</source>
</associationPredicate>
</lgCS:relations>
- <!-- C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT106958256||MAPSETRSAB|ICD10PCS|ICD10PCS|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT106958265||MTH_MAPFROMCOMPLEXITY|ICD10PCS|SINGLE SDUI|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT106958266||MTH_MAPFROMEXHAUSTIVE|ICD10PCS|N|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT106958268||MTH_MAPSETCOMPLEXITY|ICD10PCS|N_TO_N|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT106958270||MTH_MAPTOEXHAUSTIVE|ICD10PCS|N|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT106958273||TORSAB|ICD10PCS|ICD10PCS|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT112240306||FROMRSAB|ICD10PCS|ICD9CM|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT112240309||FROMVSAB|ICD10PCS|ICD9CM_2009|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT112240314||MAPSETTYPE|ICD10PCS|ICD-9-CM to ICD-10-PCS Mappings (GEMs)|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT112240316||MAPSETVERSION|ICD10PCS|2009|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT112240319||MAPSETVSAB|ICD10PCS|ICD10PCS_2009|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT112240322||MAPSETXRTARGETID|ICD10PCS|NoPCS|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT112240327||MTH_MAPTOCOMPLEXITY|ICD10PCS|SINGLE SCUI|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT112240330||SOS|ICD10PCS|This set maps ICD-9-CM codes to ICD-10-PCS. These are "General Equivalence Mappings" (GEMs) and are rule-based.|N||
C2603385|L8770856|S10872372|A16736317|CODE|MTHU000001|AT112240336||TOVSAB|ICD10PCS|ICD10PCS_2009|N||
C2603385||||CUI||AT109499260||DA|MTH|20090401|N||
C2603385||||CUI||AT110315629||ST|MTH|R|N||
C2603385||||CUI||AT116202419||MR|MTH|20090926|N||
-->
- <lgCS:relations containerName="C2603385" sourceCodingScheme="ICD9CM" sourceCodingSchemeVersion="ICD9CM_2009" targetCodingScheme="ICD10PCS" targetCodingSchemeVersion="ICD10PCS_2009" representsVersion="ICD10PCS_2009" xmlns="http://LexGrid.org/schema/2010/01/LexGrid/relations">
<lgCommon:owner>ICD10PCS</lgCommon:owner>
<lgCommon:entityDescription>This set maps ICD-9-CM codes to ICD-10-PCS. These are "General Equivalence Mappings" (GEMs) and are rule-based.</lgCommon:entityDescription>
- <properties>
- <lgCommon:property propertyName="MTH_MAPFROMCOMPLEXITY">
<lgCommon:value>SINGLE SDUI</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPFROMEXHAUSTIVE">
<lgCommon:value>N</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPSETCOMPLEXITY">
<lgCommon:value>N_TO_N</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPTOEXHAUSTIVE">
<lgCommon:value>N</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MAPSETVERSION">
<lgCommon:value>2009</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MAPSETXRTARGETID">
<lgCommon:value>NoPCS</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MTH_MAPTOCOMPLEXITY">
<lgCommon:value>SINGLE SCUI</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="DA">
<lgCommon:value>20090401</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="ST">
<lgCommon:value>R</lgCommon:value>
</lgCommon:property>
- <lgCommon:property propertyName="MR">
<lgCommon:value>20090926</lgCommon:value>
</lgCommon:property>
</properties>
- <!-- MAPSETCUI|MAPSAB |MAPSUBSETID|MAPRANK|MAPID |MAPSID|FROMID |FROMSID|FROMEXPR|FROMTYPE|FROMRULE|FROMRES|REL|RELA
C2603385 |ICD10PCS|0:0 | |AT106958276| |86.63 | |86.63 |SDUI | | |RO |approximately_mapped_to
|TOID |TOSID|TOEXPR |TOTYPE |TORULE|TORES|MAPRULE|MAPRES|MAPTYPE|MAPATN|MAPATV
|0HR6X73| |0HR6X73|SCUI |||||||||
-->
- <associationPredicate associationName="approximately_mapped_to">
- <!-- Note that "RO" gets lost in this approach...
-->
- <source sourceEntityCode="86.63">
- <target targetEntityCode="0HR6X73" associationInstanceId="AT106958276">
- <!-- NOTE: This does NOT imply any ordering in the way that map entries are returned !
-->
- <associationQualification associationQualifier="MAPSUBSETID">
<qualifierText>0:0</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="FROMTYPE">
<qualifierText>SDUI</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="FROMID">
<qualifierText>86.63</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="TOTYPE">
<qualifierText>SCUI</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="TOID">
<qualifierText>0HR6X73</qualifierText>
</associationQualification>
</target>
</source>
</associationPredicate>
- <associationPredicate associationName="XR">
- <!-- Note that approximately_mapped_to goes away. This may not be what we want?
-->
- <!-- MAPSETCUI|MAPSAB |MAPSUBSETID|MAPRANK|MAPID |MAPSID|FROMID |FROMSID|FROMEXPR|FROMTYPE|FROMRULE|FROMRES|REL|RELA
C2603385 |ICD10PCS|0:0 | |AT112240364| |89.03 | |89.03 |SDUI | | |XR ||||||||||||||
|TOID |TOSID|TOEXPR |TOTYPE |TORULE|TORES|MAPRULE|MAPRES|MAPTYPE|MAPATN|MAPATV
|||||||||||||
-->
- <source sourceEntityCode="89.03">
- <target targetEntityCode="NoPCS" associationInstanceId="AT112240364">
- <associationQualification associationQualifier="MAPSUBSETID">
<qualifierText>0:0</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="FROMTYPE">
<qualifierText>SDUI</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="FROMID">
<qualifierText>86.63</qualifierText>
</associationQualification>
- <associationQualification associationQualifier="TOID">
<qualifierText>NoPCS</qualifierText>
- <!-- This is derived from the MAPSETXRTARGETID property in MRSAT
-->
</associationQualification>
</target>
</source>
</associationPredicate>
</lgCS:relations>
</codingScheme>
Implications for CTS 2 Mapping Implementation
CTS 2 Function
Description
Scope
Update Association Status
Update the status of a association (active, inactive, canceled etc). This allows a Terminology User to activate or inactivate a given association, thus changing its availability for access by other terminology service functions
In scope for authoring API
Create Association
Relates a single specific coded concept within a specified code system (source) to a corresponding single specific coded concept (target) within the same or another code system, including identification of a specified Association type.
In scope for authoring. Querying already supported
Create Lexical Association between Coded Concepts
Relates a set of one or more coded concepts within a specified code system (source)to a corresponding set of one or more coded concepts (target) within that system or another code system using a set of lexical rules (matching algorithms) to generate the Association. The "Source Search Criteria" allows for identification of a subset of the Source Code System to apply the matching algorithm to, if required (this may include limiting the version of the code system).
Not in scope for CTS 2
Create Rules Based Association between Coded Concepts
Relates a set of zero or more coded concepts within a specified code system (source)to a corresponding set of zero or more coded concepts (target) within that system or another code system using a set of description logic or inference rules that either assert or infer Associations. The "Source Search Criteria" allows for identification of a subset of the Source Code System to apply the matching algorithm too, if required (this may include limiting the version of the code system).
Not in scope for CTS 2
Solution Architecture
Data Access Layer
LexEVS lacks a generalized Read/Write interface that can support Authoring and incremental Coding Scheme changes. Also, database access is not isolated. Database-specific code is intermixed with the Service Layer, as well as Extensions. To make LexEVS more able to handle Authoring, while at the same time providing a clean, centralized Database Access Layer, these are the requirements:
- Service Layer code should not call any JDBC code other than a Data Access Interface
- The Data Access Layer should allow connection pooling
- The Data Access Layer should expose 'Service' or 'Repository' Interfaces to the Service Layer.
- Transactions should be well defined
- Allow for Backwards Compatibility
- Inserts, Updates, Selects, and Deletes should cascade the Object hierarchy if desired
- Service-Exposed Interfaces should use the Castor-generated beans.
- Batch inserts should be supported
- Lucene access should be included in the Data Access Layer
- Registry accesss should be included in the Data Access Layer.
- Expose an Event-Driven framework to allow users to insert business rules to control access to the database
- In terms of System Resource responsibilities, the Data Access Layer should be responsible for:
- Detecting the LexGrid Schema version
- Detecting the Database Type (MySQL, Oracle... etc)
- Producing appropriate implementations of the Database Access code given the above
- Loading and initializing all schemas on install
- Tracking loaded Coding Schemes and other resources
- All database admin functions (remove Coding Scheme, index, compute transitivity, etc)
Cross product dependencies
Include a link to the Core Product Dependency Matrix![]() .
.
Changes in technology
Include any new dependencies in the Core Product Dependency Matrix![]() and summarize them here.
and summarize them here.
Assumptions
List any assumptions.
Risks
List any risks.
Detailed Design
Data Access Layer
Structure
Main Components:
- Database
- An access point for CRUD (Create, Read, Update, Delete) operations
- Will contain a ServiceManager Interface, which will expose Service Layer consumable CRUD services.
- Contains logic for LexGrid Schema Version detection and Database Type detection.
- Serves as the Transaction Demarcation Layer
- System Resources
- Provides various system-level services
- Registry
- Maintains a list of available Resources (loaded Coding Schemes, Histories, etc)
- Index
- Provides a Lucene-based indexing service
Sub Components:
- (Data Access Object) DAO Manager
- Provides fine-grained CRUD access to the Database
- Is NOT Transaction aware -- all transactions must be defined by the calling services
- Does NOT cascade
- This is done to allow the the Service to define exact transaction granularity
- Event framework is implemented in the individual DAOs, not the Services

Domain Driven Design
The LexEVS Data Access Layer loosely follows the Domain Driven Design (DDD) Principals.
DDD Principals and the LexEVS Data Access Layer equivalent:
- DDD Entities
- In DDD, an 'Entity' is an Object that has Identity and may have 'Versions'. In other words, if some part of an Entity changes, the identity of the Entity does not change, but it can be considered a different 'Version'
- LexEVS Data Access Layer Entities
- In LexEVS, the idea of "having identity" and "having a version" are generally encompassed by Model Objects that implement the 'Versionable' Interface.
- DDD Value Objects
- A Value Object does not maintain an identity, therefore, if its state changes, the Object itself is now something different.
- Entities contain Value Objects
- LexEVS Data Access Layer Value Objects
- All Model Objects in LexEVS that do NOT implement the 'Versionable' interface are considered Value Objects.
- Considerations for LexEVS Value Objects:
- Value Objects are NOT directly Updatable
- Value Objects may only be Updated via a Update of the Containing Entity
- Value Objects may only be Deleted via a Delete of the Containing Entity
- Value Objects may be inserted independently given the ID of the Containing Entity
- If a Value Object changes, its Containing Entity's Version will change
- Examples: AssociationQualifiers, PropertyQualifiers, Sources, etc...
- DDD Aggregate Roots
- A DDD Aggregate Root is a collection of Entities that share a common lifecycle.
- All children are accessed through the top-level Object, or Root.
- All CRUD operations are cascaded within the Aggregate Root boundary
- LexEVS Data Access Layer Aggregate Roots
- LexEVS has a very heirarchical Object Model, meaning that most Entities are dependent upon the lifecycle of a parent. For instance, if a Coding Scheme is removed, all containing Concepts are removed. A Concept cannot exist in LexEVS without a Coding Scheme.
- So how to define Aggregate Root boundaries? In LexEVS, almost everything that is an Entity can also be considered an Aggregate Root.
- DDD Repository
- Repositories are for persisting Aggregate Roots. The aim is to apply Collection Semantics to Domain Objects. For instance, add(...), get(...), and so on.
- LexEVS Repository
- LexEVS deviates from the idea of a 'Repository' for several reasons:
- Finer grained inserts are needed by the loaders. For example, in some instances we may need to insert something independently that is not an Aggregate Root, like a PropertyQualifier.
- Because we could in theory consider all of our Entities Aggregate Roots, we would have a proliferation of Repositories.
- LexEVS deviates from the idea of a 'Repository' for several reasons:
Service-Based CRUD and Component Interaction
General Component Flow:
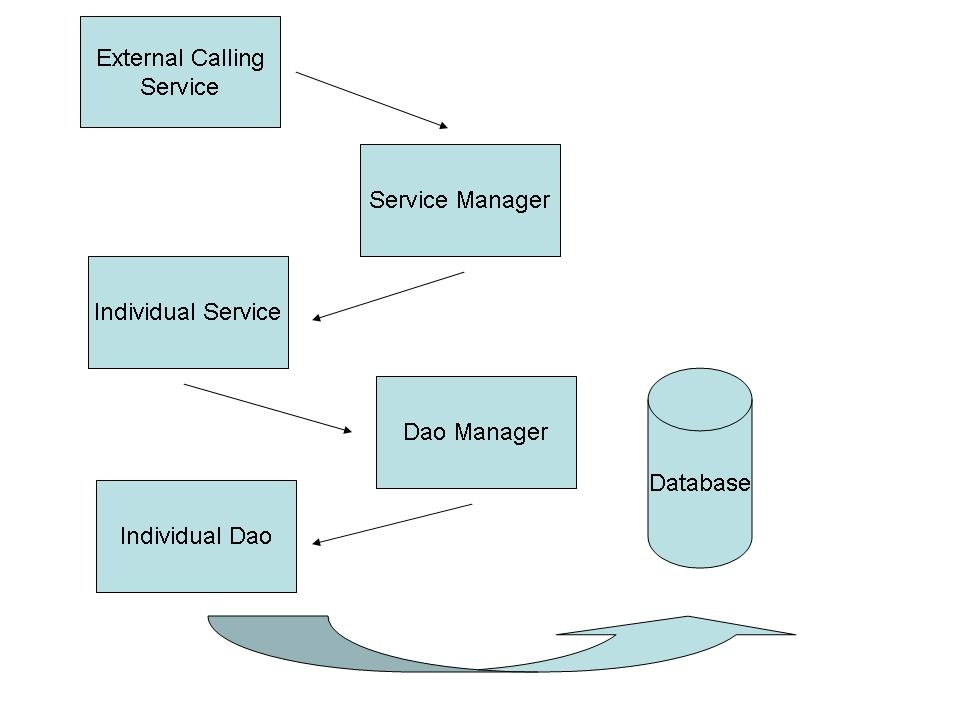
External Calling Service
The Component, API, or Application that requires access to the database. The reference to the Service Manger is obtained through a Service Locator pattern, or by other means outside the scope of the Data Access Layer. The External calling service does not (and should not) use any JDBC specific code, including Transactional Demarcation.
Service Manager
The Service Manager is the main entry point to all of the Data Access Services. The Service Manager provides a centralized reference for all of the available Database Access Services, allowing clients to select the Service or Services that they require.
Individual Service
Database Access is broken into groups of 'Services'. Each Service will be a logical grouping of functions loosely based on packages of the Object Model. A service serves these rols:
- Provides transaction boundaries
- Serves as a facade for the fine-grained DAO API.
- Is always implementation independent.
DAO Manager
The DAO Manager serves the same purpose as the Service Manager -- to provide a central lookup point for all available DAOs in the system.
The DAO Manager is implementation independent, so it must follow certain rules:
- The DAO Manager will obtain references to individual DAOs through a factory, never directly. This decouples them from the actual implementation of the DAO, and allows underlying Database Type and LexGrid Schema Version checking mechanisms to be put in place
- There will be no implementation specific code in the DAO Manager.
Individual DAOs
Each individual DAO will be responsible for a logical set of CRUD database operations. DAOs themselves are expected to be implementation specific, MAY be LexGrid Schema Version specific and MAY be Database Type specific. So, for example, there may be one DAO for Oracle, one for DB2, and so on. The DAO is expected to provide enough information about itself for factories to be able to select the appropriate DAO for the DAO Manager.
DAOs may be implemented in any framework, as long as the adhere to the Interface contract of the DAO.
DAOs may NOT define Transaction boundaries within themselvs.
DAOs MUST fire the appropriate events as content is updated, inserted, or deleted.
Event Framework
The Data Access layer will support an Event-Based framework to allow External Calling Services an access point to monitor the changing state of the Database The Data Access Layer Event Framework will follow these guidelines:
- Any CRUD operation on a Versionable Entity will fire an Event
- External Services will be able to register an arbitrary number of listeners
- An Insert Operation will fire an event of this type:
Insert Event |
|
|---|---|
Parameter |
Output |
Item to be inserted |
A boolean indicating whether or not the insert should take place |
Delete Event |
|
|---|---|
Parameter |
Output |
Item to be deleted |
A boolean indicating whether or not the delete should take place |
Update Event |
|
|---|---|
Parameter |
Output |
Item to be updated (before changes) |
|
Item to be updated (after changes) |
A boolean indicating whether or not the update should take place |
Implementation
Database
Ibatis
Apache Ibatis http://ibatis.apache.org/![]() is a framework for decoupling SQL code from Java code. All SQL code is defined in XML files as opposed to in the Java classes themselves, making updates and edits to the SQL. Also, SQL code can be modified without recompiling the system.
is a framework for decoupling SQL code from Java code. All SQL code is defined in XML files as opposed to in the Java classes themselves, making updates and edits to the SQL. Also, SQL code can be modified without recompiling the system.
Reasons for Ibatis:
- Allows direct access to the SQL code, allowing for complex, optimized queries
- Enables a clear distinction between Java code and SQL code
- Pre-mapped result sets and Row Mappers to convert from Database Row -> Domain Object
An example Ibatis XML document is shown below. Note that the SQL code, as well as the logic for assembling the results, is decoupled from the Java implementation: 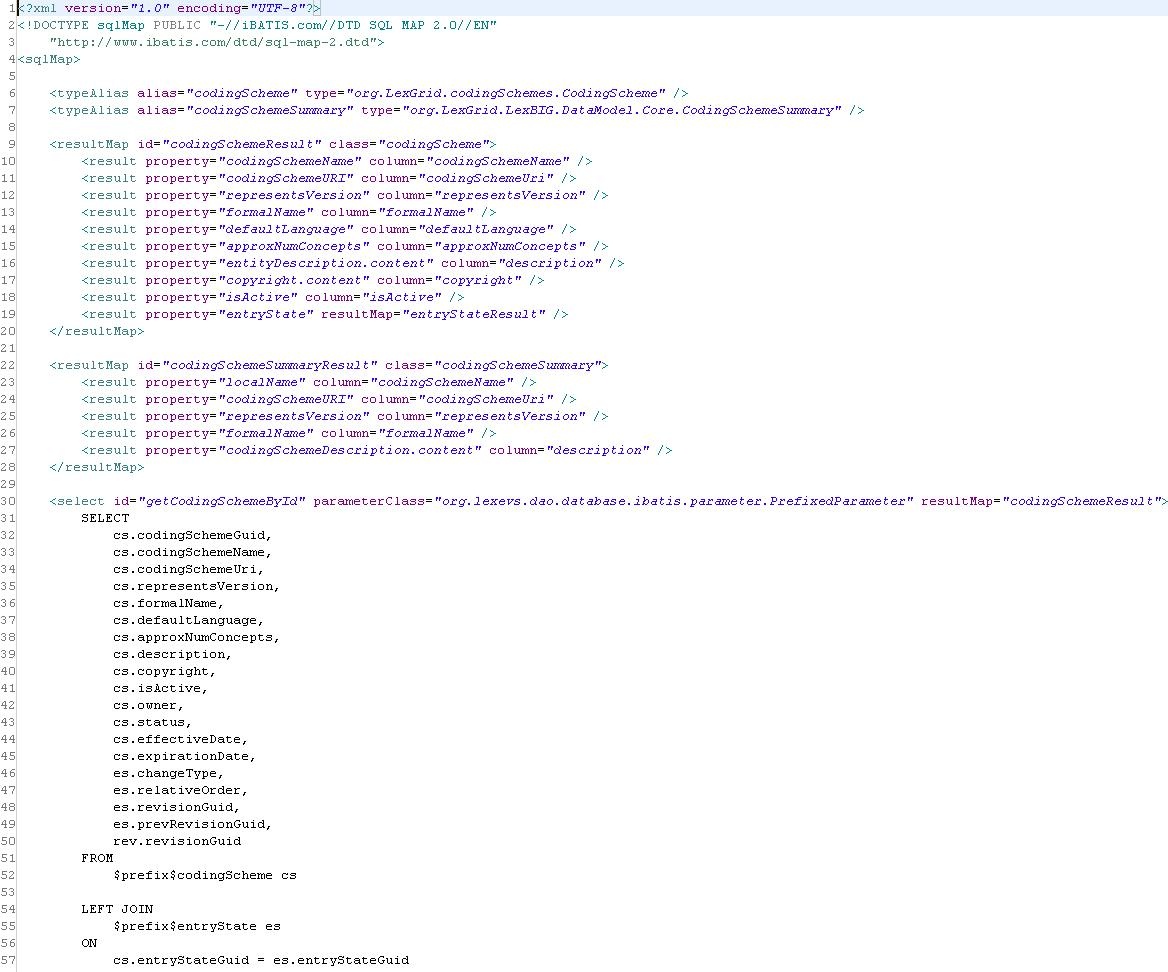
Ibatis vs. Hibernate
Hibernate is an Object Relational Mapping tool, Ibatis is not. Hibernate aims to abstract the developer from building SQL code, as all SQL is generated by the framework. Ibatis does not build or generate SQL code, but gives the user direct control of the SQL.
Hibernate assumes a certain database structure, as well as a specific Object Model structure to be able to function properly. There are several problems with using Hibernate with LexEVS.
- The LexEVS Object Model does not track the Id of an Object ('Id' meaning the unique database key)
- Associations in the Object Model are Uni-directional ONLY - even if they are Bi-directional in the database. This means that even though a certain Object may be dependent on the lifecycle of a parent Object, there is no direct refrence from Child -> Parent
- LexEVS must support Horizontal Partitioning of the Database based on Coding Scheme, so every Coding Scheme in LexEVS must be able to be partitioned into its own set of schema tables. This requires dynamically changing the table name at query-time to account for the different sets of tables. Hibernate does not handle this efficiently.
Ibatis vs. Spring JDBC
Spring JDBC is a JDBC framework that abstracts the developer from boilerplate JDBC code, such as managing connections, error handling, mapping rows to Objects, etc. It uses Template Patterns to provide commonly used JDBC functionality. Spring JDBC is powerful, flexible, and fast -- but it does not decouple the SQL code from the Java Code. Ibatis accomplishes much of the same thing as Spring JDBC -- they both allow dynamic SQL building and direct control of the SQL code.
Caching
Caching commonly accessed data is critical for performance, and the DAO Layer will have a built-in caching framework to accommodate this. The framework is annotation-based and could be generalized to other use-cases, not just the DAO layer.
Annotations
@Cacheable
The @Cacheable annotation marks a class as being eligible for method caching. Classes without this annotation will not considered by the Caching framework
This annotation accepts 2 parameters:
Parameter Name |
Description |
Required |
|---|---|---|
cacheName |
The unique name of the cache. This cache may be shared between classes, or each class may have its own unique cache. |
YES |
cacheSize |
The number of cached elements to be held in memory. Once the limit is reached, the element that has be accessed |
NO |
@CacheMethod
The @CacheMethod annotation is placed on an individual method to be cached. Method caching follows the following guidelines:
- The String representation of all parameters are combined to form the 'Key'. On subsequent calls to the method, the framework will compare the parameters to determine if the result can be resolved from the cache.
@CacheMethod public CodingScheme getCodingSchemeById(String codingSchemeId)
In the example above, the String 'codingSchemeId' is evaluated as the cache 'key'. If future calls to the method have the some 'codingSchemeId' parameter - the method will not execute, and the result will be resolved from the cache.
Determining Cache Keys
NOTE: The cache key is determined by the 'toString()' representation of every parameter passed to the method.
@ClearCache
If a call to a method in a Cacheable class will invalidate the cache, the @ClearCache annotation may be used to reset the cache. An example use-case if this would be an 'update' method. The 'update' will change the underlying data in the data store, but the cache will still contain the old data. A @ClearCache annotation may be added to any 'update' method to reset the cache whenever the underlying data may have changed.
Registry
LexEVS 6.0 marks the move to a Database-based Registry. All previous releases of LexEVS relied on a file-system based XML Registry:
<?xml version="1.0" encoding="UTF-8"?> <LexBIG_Registry> <variables> <lastUpdateTime value="1265818643217" /> <lastUsedDBIdentifer value="a5" /> <lastUsedHistoryIdentifer value="a0" /> </variables> <codingSchemes> <codingScheme urn="urn:oid:11.11.0.1" dbURL="jdbc:mysql://bmidev3:3307/junit" dbName="" prefix="lba5_" status="active" tag="" version="1.0" deactivateDate="0" lastUpdateDate="1265818643217" /> </codingSchemes> <histories /> </LexBIG_Registry>
In LexEVS 6.0, this will be represented in two database tables:

Motivations for a Database-based Registry:
- Allow multiple LexEVS installations to share a Registry without having to access the same filesystem. In previous releases, either each LexEVS installation had to maintain a copy of the Registry XML file, or the installations had to be on the same physical file-system.
- Avoid XML locking problems. Preventing concurrent edits to an XML file is error-prone. In previous versions of LexEVS, this was done by 'lock' files placed on the filesystem to alert other JVMs that an edit to the XML was being done. When using a database, the database's transaction framework will replace the 'lock' files, preventing concurrent updates.
Backwards Compatibility
LexEVS will be Backwards Compatible with N-1 releases of LexEVS. For version 6.0, LexEVS will be able to be a drop-in replacement for LexEVS 5.1.
Registry
LexEVS 6.0 will use a database-based Registry -- whereas all previous releases have used a file-system XML based Registry file.
- LexEVS 6.0 will be able to Read/Write to the XML based registry as before, with some exceptions:
- No new loaded Coding Schemes may be added to an XML-based Registry.
- All new loaded Content will be registered to the database Registry.
- LexEVS 6.0 will be able to perform admin operations on an XML Registry (remove an entry, change a tag, deactivate, etc).
Database
Database Backwards Compatibility will be handled on the DAO level. The DAO Manager will selected the appropriate DAO from the pool based on the table structure of the Resource requested.
Running LexEVS in a Mixed Environment
LexEVS 6.0 and 5.1 are able to share the same set of Resources (database, loaded content, etc), with the following stipulations:
- All changes done by a LexEVS 5.1 installation will be available to the LexEVS 6.0 installation using the same resources.
- Content loaded by a LexEVS 5.1 installation will be accessible to the LexEVS 6.0 installation.
Content loaded by a LexEVS 6.0 installation will NOT be accessible to the LexEVS 5.1 installation.
Single Database Table vs. Multiple Database Tables
LexEVS 6.0 will include an option to load CodingSchemes into a single, common set of tables, or individual sets of tables for each CodingSchemes. Some considerations for each option:
- Single Table Advantages:
- Limits Table proliferation in the database.
- All Coding Schemes centralized into one table.
- Single Table Disadvantages:
- Possible performance penalty. A query will be executed against the common table, which will be many times larger than the ontology loaded as an individual table.
To the underlying API, the actual table that data is stored in will be abstracted. All queries will except a Prefix -- whether that prefix is from the common table, or from an individual table, the query remains the same.
The prefix will be stored in the registry table of the database. The prefixed is then obtained given a CodingScheme URI and Version. Every CodingScheme will be loaded in the Registry, and the prefix will be retrievable given its URI and Version.
Prefixes are automatically injected into SQL statements to direct the SQL to the appropriate table. For instance:
SELECT FROM $prefix$entity WHERE ...
Prior to the execution of the SQL statement, the '$prefix$' placeholder will be replaced with the actual prefix retrieved from the Registry.
Loader Post Processor
In order to facilitate extra Processing at the end of an Ontology load, LexEVS 6.0 will support Loader Post Processors.
A Loader Post Processor is logic that will be executed when the actual content load to the database is complete, but before the Lucene Indexing occurs. It will be implemented as an Extension - meaning that users may place jars in the LexEVS class path and introduce Loader Post Processors without the need to recompile.
The Loader Post Processor interface is straightforward:
public interface LoaderPostProcessor extends GenericExtension {
public void runPostProcess(AbsoluteCodingSchemeVersionReference reference);
}
Note: that this is considered a GenericExtension and must be registered and declared as such.
A Loader Post Processor may apply any logic that is required -- there are not constraints as to the scope. A Loader Post Processor may update database content, delete content, reference other loaded ontologies, etc.
An example Loader Post Processor is shown below -- this example will update the Approximate Number of Loaded Entities field of a Coding Scheme:
package org.LexGrid.LexBIG.Impl.loaders.postprocessor;
import org.LexGrid.LexBIG.DataModel.Core.AbsoluteCodingSchemeVersionReference;
import org.LexGrid.LexBIG.DataModel.InterfaceElements.ExtensionDescription;
import org.LexGrid.LexBIG.Exceptions.LBException;
import org.LexGrid.LexBIG.Exceptions.LBParameterException;
import org.LexGrid.LexBIG.Extensions.Generic.GenericExtension;
import org.LexGrid.LexBIG.Extensions.Load.postprocessor.LoaderPostProcessor;
import org.LexGrid.LexBIG.Impl.Extensions.AbstractExtendable;
import org.LexGrid.LexBIG.Impl.Extensions.ExtensionRegistryImpl;
import org.LexGrid.codingSchemes.CodingScheme;
import org.lexevs.dao.database.service.codingscheme.CodingSchemeService;
import org.lexevs.dao.database.service.entity.EntityService;
import org.lexevs.locator.LexEvsServiceLocator;
public class ApproxNumOfConceptsPostProcessor extends AbstractExtendable implements LoaderPostProcessor {
private static final long serialVersionUID = 2828520523031693573L;
public static String EXTENSION_NAME = "ApproxNumOfConceptsPostProcessor";
public void register() throws LBParameterException, LBException {
ExtensionRegistryImpl.instance().registerGenericExtension(
super.getExtensionDescription());
}
@Override
protected ExtensionDescription buildExtensionDescription() {
ExtensionDescription ed = new ExtensionDescription();
ed.setDescription("ApproxNumOfConceptsPostProcessor");
ed.setName(EXTENSION_NAME);
ed.setExtensionBaseClass(GenericExtension.class.getName());
ed.setExtensionClass(this.getClass().getName());
return ed;
}
public void runPostProcess(AbsoluteCodingSchemeVersionReference reference) {
EntityService entityService = LexEvsServiceLocator.getInstance().getDatabaseServiceManager().getEntityService();
CodingSchemeService codingSchemeService = LexEvsServiceLocator.getInstance().getDatabaseServiceManager().getCodingSchemeService();
String uri = reference.getCodingSchemeURN();
String version = reference.getCodingSchemeVersion();
long entities = entityService.getEntityCount(uri, version);
CodingScheme codingScheme = codingSchemeService.getCodingSchemeByUriAndVersion(uri, version);
codingScheme.setApproxNumConcepts(entities);
codingSchemeService.updateCodingScheme(uri, version, codingScheme);
}
}
Value Set Definition
Value Set Definition with in the LexGrid logical model defines the contents of Value Set. The contents are concept codes defined in referencing Code System. Value Set can contain concept codes from one or more Code Systems.
Compared to ISO 11179 model:
The LexGrid "value set definition" is analogous to the 11179 enumerated conceptual domain. We support the notion of an intrinsically defined enumerated domain, so the 11179 enumerated conceptual domain is really the output of the resolve value set definition function.
Value meanings are identified by entity codes within a given code system. The mapping between permissible values and value meanings is currently accomplished via a mapping association, where we treat the set of permissible values as a "mini code system". An example of how this might work is that HL7 has a set of permissible values of "M", "F", "U", which are in the administrative gender "code system". In the pure HL7 context, these might well map to the equivalent value meanings identified by "M", "F" and "U". If, however, we were using, say, the UMLS as a source of meaning, the same codes would map to the corresponding UMLS CUIs.
Compared to HL7 Value Set:
The term "value set", when discussed in the context of HL7 can be somewhat ambiguous. There are at least three related artifacts that are sometimes called "value sets", including 1) a definition or algorithm that, when interpreted, produces a set of concept codes, 2) the actual set of concept codes that result from the execution of a the definition or algorithm, and 3) a subset of this set of concept codes coupled with appropriate designations and identifying information. For this reason, the LexEVS model uses the names "value set definition", "value set resolution" and "pick list definition", "pick list resolution" respectively to represent the three different senses of "value set" described above.
Value Set Definition logical model
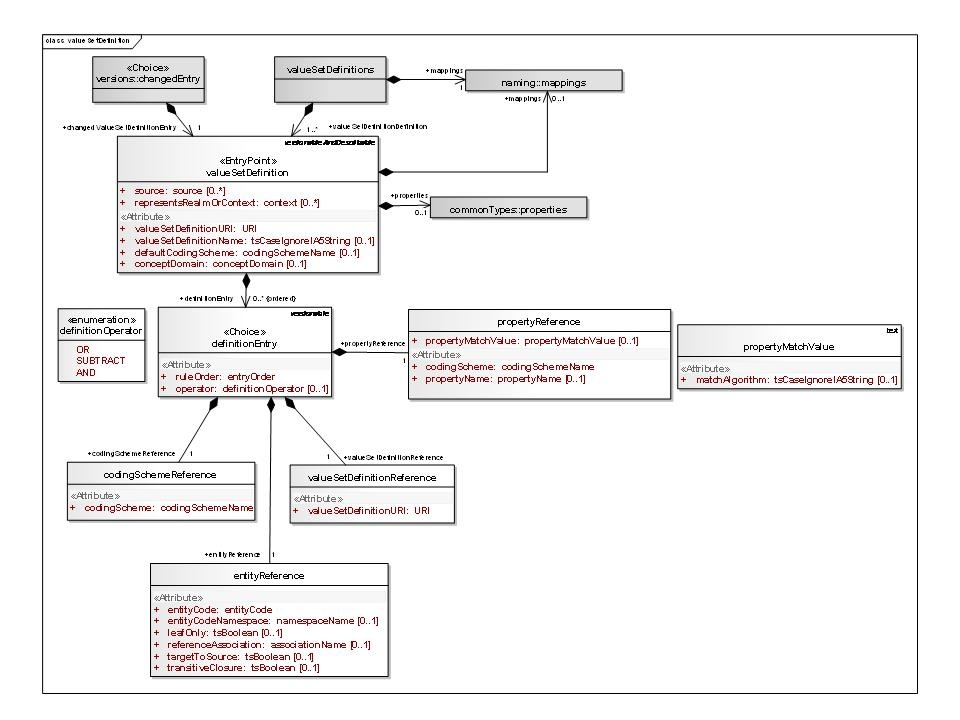
Value Set Definition logical model description
Value Set Definition
A definition of a given value set. A value set definition can be a simple description with no associated value set entries, or it can consist of one or more definitionEntries that resolve to an enumerated list of entityCodes when applied to one or more codingScheme versions.
Attributes of Value Set Definition :
Source: The local identifiers of the source(s) of this property. Must match a local id of a supportedSource in the corresponding mappings section.
representsRealmOrContext: The local identifiers of the context(s) in which this value set applies. Must match a local id of a supportedContext in the corresponding mappings section.
valueSetDefinitionURI: The URI of this value set definition.
valueSetDefinitionName: The name of this value set definition, if any.
defaultCodingScheme: Local name of the primary coding scheme from which the set is drawn. defaultCodingScheme must match a local id of a supportedCodingScheme in the mappings section.
conceptDomain: Local name of the concept domain. When present, the contents of value set are considered to be binded to this specific concept domain. conceptDomain must match a local id of a supportedConceptDomain in the mappings section.
Value Set Definition Entry
A reference to an entry code, a coding scheme, entity code property name or value, or another value set definition along with the instructions about how the reference is applied. Definition entries are applied in entryOrder, with each successive entry either adding to or subtracting from the final set of entity codes.
Attributes of Value Set Definition Entry :
ruleOrder: The unique identifier of the definition entry within the definition as well as the relative order in which this entry should be applied
operator: How this entry is to be applied to the value set
Coding Scheme Reference
A reference to all of the entity codes in a given coding scheme.
Attributes of Coding Scheme Reference :
codingScheme: The local identifier of the coding scheme that the entity codes are drawn from . codingSchemeName must match a local id of a supportedCodingScheme in the mappings section.
Value Set References
A reference to the set of codes defined in another value set definition.
Attributes of Value Set Reference :
valueSetDefinitionURI: The URI of the value set definition to apply the operator to. This value set may be contained within the local service or may need to be resolved externally.
Entity Reference
A reference to an entityCode and/or one or more entityCodes that have a relationship to the specified entity code.
Attributes of Entity Reference :
entityCode: The entity code being referenced.
entityCodeNamespace: Local identifier of the namespace of the entityCode. entityCodeNamespace must match a local id of a supportedNamespace in the corresponding mappings section. If omitted, the URI of the defaultCodingScheme will be used as the URI of the entity code.
leafOnly: If true and referenceAssociation is supplied and referenceAssociation is defined as transitive, include all entity codes that are "leaves" in transitive closure of referenceAssociation as applied to entity code. Default: false
referenceAssociation: The local identifier of an association that appears in the native relations collection in the default coding scheme. This association is used to describe a set of entity codes. If absent, only the entityCode itself is included in this definition.
targetToSource: If true and referenceAssociation is supplied, navigate from entityCode as the association target to the corresponding sources. If transitiveClosure is true and the referenceAssociation is transitive, include all the ancestors in the list rather than just the direct "parents" (sources).
transitiveClosure: If true and referenceAssociation is supplied and referenceAssociation is defined as transitive, include all entity codes that belong to transitive closure of referenceAssociation as applied to entity code. Default: false
Property Reference
A reference to a propertyName or propertyValue and matchAlgoritm to use.
Attributes of Property Reference :
codingScheme: The local identifier of the codingScheme that this propertyReference will be resolved against. codingScheme must match a local id of a supportedCodingscheme in the corresponding mappings section.
propertyName: The local identifier to be used to restrict the entities to have property with this name. Must match a local id of a supportedProperty in the corresponding mappings section.
propertyMatchValue: Value to be used to restrict entity property. matchAlgorithm can be used in conjunction to get matching entity properties.
Property Match Value
Property match value to be used to restrict entity property. matchAlgorithm can be used in conjunction to get matching entity properties.
Attributes of Property Match Value :
matchAlgorithm: Algorithm to be used in conjunction with propertyValue.
Definition Operator
The description of how a given definition entry is applied.
Attributes of Definition Operator :
OR: Add the set of entityCodes described by the currentEntity to the value set. (logical OR)
SUBTRACT: Subtract (remove) the set of entityCodes described by the currentEntity to the value set. (logical NAND)
AND: Only include the entity codes that are both in the value set and the definition entry. (logical AND)
Possible forms of Value Set Definitions
- Definition containing just the reference to Code System - includes all the concept codes in the referencing code system.
- Definition containing just the reference to other Value Set Definition -includes all the concept codes defined in the referencing Value Set Definition.
- Definition containing reference to Code System plus concept codes - includes individual concept codes defined in the definition from the referencing code system.
- Definition containing reference to Code System plus concept codes plus relationship plus additional rules (leaf only, immediate children, matching property name/value etc) - includes concept codes from the referencing code system that satisfies the rule set defined in the definition.
- Combination of any of the above with OR/AND/SUBTRACT operations.
Definition of the Value Set could be as simple as specifying just individual concept codes or specifying to include all the children of concept 'Body Structure' from Code System 'SNOMED CT' to complex definition containing multiple rule sets.
Here are some fictitious examples of Value Set Definitions
Example 1

Example 2
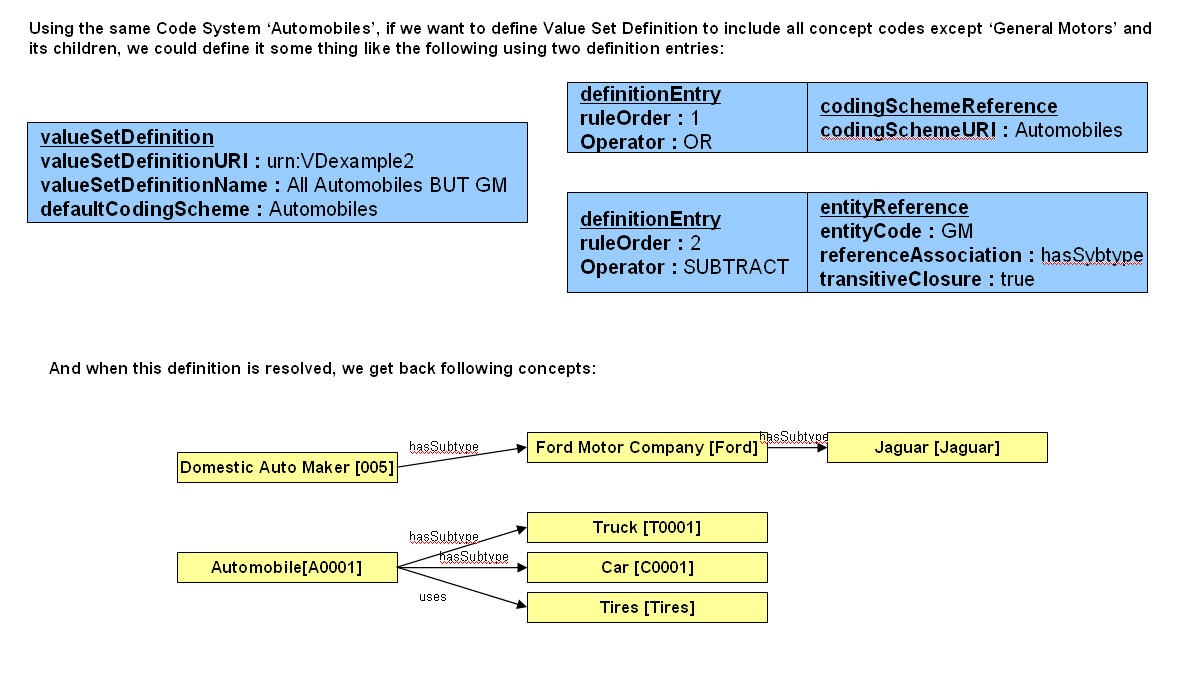
Value Set Definition Resolution
- A value set definition has to be made against a specific version of a code system.
- But it doesn't have to be resolved against the same version.
- Even a simple list (a, b, c, d) needs to be resolved as, at some future date, "c" might be retired.
- Resolution does not create static artifact.
Value Set Definition Versions
Value Set Definitions are versioned. The version of Value Set Definition changes when ever the definition is changed, it could be adding or removing Code System reference or changes in the rule set.
Value Set Services
LexEVS Value Set Services is an integral part of LexEVS Core API. It provides:
- Ability to load Value Set Definitions into LexGrid repository
- Ability to apply user restrictions and dynamically resolve the definitions during run time
- Ability to author Value Set Definition
Major functions provided by Value Set Definition Services
- Administration functions:
- Ability to load Value Set Definitions into LexGrid repository.
- Ability to remove Value Set Definitions from LexGrid repository.
- Here are some of the admin methods available:
- loadValueSetDefinition(ValueSetDefinition vddef, String systemReleaseURI) - Loads supplied valueSetDefinition object
- loadValueSetDefinition(InputStream inputStream, boolean failOnAllErrors) - Loads valueSetDefinitions found in inputStream
- loadValueSetDefinition(String xmlFileLocation, boolean failOnAllErrors) - Loads valueSetDefinitions found in input xml file
- removeValueSetDefinition(URI valueSetDefinitionURI) - Removes supplied value set definition from the system
- removeAllValueSetDefinitions() - Removes all value set definitions from the system
- Query functions:
- Ability to list all the Value Set Definitions loaded in the system.
- Ability to dynamically resolve Value Set Definition with/without user supplied restrictions.
- Ability to check if a concept code is part of given Value Set.
- Ability to check if one Value Set is sub set of other Value Set.
- Here are some of the query methods available:
- isConceptInSet(String entityCode, URI valueSetDefinitionURI) - Determine if the supplied entity code is a valid result for the supplied value set and, if it is, return the particular codingSchemeVersion that was used
- isConceptInSet(String entityCode, URI entityCodeNamespace, CodingSchemeVersionOrTag csvt, URI valueSetDefinitionURI) - Similar to previous method, this method determine if the supplied entity code and entity namespace is a valid result for the supplied value set when resolved against supplied Coding Scheme Version or Tag
- resolveValueSetDefinition(URI valueSetDefinitionURI, AbsoluteCodingSchemeVersionReferenceList csVersionList) - Resolve a value set using the supplied set of coding scheme versions
- ResolvedValueSetDefinition : A resolved Value Set Definition containing the Coding Scheme Version reference list that was used to resolve the Value Set and an iterator for resolved concepts
- getValueSetEntitiesForTerm(String term, URI valueSetDefinitionURI, String matchAlgorithm) - Resolves the value set supplied and restricts to the term and matchAlgorithm supplied
- ResolvedValueSetCodedNodeSet : Contains the codingScheme URI and Version that was used to resolve and the CodedNodeSet. Note : the CodedNodeSet is unresolved
- isSubSet(URI childValueSetDefinitionURI, URI parentValueSetDefinitionURI) - Check whether childValueSetDefinitionURI is a child of parentValueSetDefinitionURI
- getValueSetDefinition(URI valueSetDefinitionURI) - Returns value set definition for supplied value set definition URI
- listValueSetDefinitions(String valueSetDefinitionName) - Return the URI's for the value set definition(s) for the supplied name
- getAllValueSetDefinitionsWithNoNames() - Return the URI's of all unnamed value set definition(s)
- getCodingSchemesInValueSetDefinition(URI valueSetDefinitionURI) - Returns list of coding scheme summary that is referenced by the supplied value set definition URI
- isValueSet(String entityCode, String codingSchemeName, CodingSchemeVersionOrTag csvt) - Determine if the supplied entity code is of type valueSet in supplied coding scheme and, if it is, return the true, otherwise return false
- Authoring functions:
- valueSetDefinition and definitionEntry classes are versionable entities in LexGrid model. Following authoring functions can be performed on them:
- NEW : Create new Value Set Definition or add new defintionEntry to existing Value Set Definition.
- MODIFY : Modify existing attributes of Value Set Definition or definitionEntry.
- REMOVE : Ability to completely remove Value Set Definition or definitionEntry. This is not the same as deprecated, as the entity ceases to exist in future versions.
- valueSetDefinition and definitionEntry classes are versionable entities in LexGrid model. Following authoring functions can be performed on them:
Refer to Revision section of this document for information on how revisions can be applied and how LexEVS handles them.
CTS 2 specific Value Set Services
CTS 2 specification uses term "Value Set" which is basically LexEVS implementation of "Value Set Definition". Though, CTS 2 implementation functions uses term "Value Set", internally, the LexEVS Value Set Definition Services are used. CTS 2 specification contains several Value Set specific profiles as described in the above High Level Architecture section. All of these functions can be called using CTS 2 interface as described in the above High Level Architecture section.
Here are CTS 2 profiles specific to Value Sets:
- Administration profile:
Import Value Set Version
Ability to import values sets
- Query profile:
List Value Sets
The ability to determine what value sets are available to a Terminology Service. This includes seeing a listing of the available value sets that match some search criteria, as well as the details pertaining to each value set available to the terminology service.
Return Value Set Details
The ability to retrieve a specific value set, with associated attributes and other metadata.
List Value Set Contents
The ability to see a listing of specific concepts, as well as the details pertaining to each concept in any of the given value sets available to a terminology service.
Check Concept Value Set Membership
The ability to validate that a given concept exists in a given value set.
Check Value Set Subsumption
Determine whether one of the two supplied value sets subsumes the other
- Authoring profile:
Create Value Set
The ability to create a dynamic value set that is defined by a computable expression that can be resolved to an exact list of coded concepts at any given point in time.
Maintain Value Set
Update properties or expression of a value set definition (extensional and intensional value sets).
Update Value Set Status
The ability to modify the status of a value set.
Load Scripts
Scripts to load Value Set Definitions into LexEVS system will be located under 'Admin' folder of LexEVS install directory. This loader scripts will only load data in XML file that is in LexGrid format.
Value Set Definition Loader
LoadValueSetDefinition.bat for Windows environment and LoadValueSetDefinition.sh for Unix environment.
Both these scripts takes in following parameters :
-in |
Input <uri> URI or path specifying location of the source file. |
-v |
Validate <int> Perform validation of the candidate resource without loading data. |
Example:
sh LoadValueSetDefinition.sh -in "file:///path/to/file.xml"
Pick List Definition
An ordered list of entity codes and corresponding presentations drawn from a resolved value set definition.
Pick List Definition logical model
Here is a UML representation of Pick List Definition with in LexGrid 201001 model :

Pick List Definition logical model description
Pick List Definition
An ordered list of entity codes and corresponding presentations drawn from a resolved value set definition.
Attributes of Pick List Definition :
Source: The local identifiers of the source(s) of this pick list definition. Must match a local id of a supportedSource in the corresponding mappings section.
pickListId: An identifier that uniquely names this list within the context of the collection.
representsValueSetDefinition: The URI of the value set definition that is represented by this pick list
defaultEntityCodeNamespace: Local name of the namespace to which the entry codes in this list belong. defaultEntityCodeNamespace must match a local id of a supportedNamespace in the mappings section.
defaultLanguage: The local identifier of the language that is used to generate the text of this pick list if not otherwise specified. Note that this language does NOT necessarily have any coorelation with the language of a pickListEntry itself or the language of the target user. defaultLanguage must match a local id of a supportedLanguage in the mappings section.
defaultSortOrder: The local identifier of a sort order that is used as the default in the definition of the pick list
defaultPickContext: The local identifiers of the context used in the definition of the pick list.
completeSet: True means that this pick list should represent all of the entries in the resolved value set definition. Any active entity codes that aren't in the specific pick list entries are added to the end, using the designations identified by the defaultLanguage, defaultSortOrder and defaultPickContext. Default: false
Pick List Entry Node
An inclusion (pickListEntry) or exclusion (pickListEntryExclusion) in a pick list definition
Attributes of Pick List Entry Node :
pickListEntryId: Unique identifier of this node within the list.
Pick List Entry
An entity code and corresponding textual representation.
Attributes of Pick List Entry :
pickText: The text that represents this node in the pick list. Some business rules may require that this string match a presentation associated with the entityCode
pickContext: The local identifiers of the context(s) in which this entry applies. pickContext must match a local id of a supportedContext in the mappings section
entryOrder: Relative order of this entry in the list. pickListEntries without a supplied order follow the all entries with an order, and the order is not defined.
entityCode: Entity code associated with this entry.
entityCodeNamespace: Local identifier of the namespace of the entity code if different than the pickListDefinition defaultEntityCodeNamespace. entityCodeNamespace must match a local id of a supportedNamespace in the mappings section.
propertyId: The property identifier associated with the entityCode and entityCodeNamespace that the pickText was derived from. If absent, the pick text can be anything. Some terminologies may have business rules requiring this attribute to be present.
isDefault: True means that this is the default entry for the supplied language and context.
matchIfNoContext: True means that this entry can be used if no contexts are supplied, even though pickContext ispresent.
Language: The local name of the language to be used when the application/user supplies a selection language matches. If absent, this matches all languages. language must match a local id od of a supportedLanguage in the mappings section.
Pick List Entry Exclusion
An entity code that is explicitly excluded from a pick list.
Attributes of Pick List Entry Exclusion:
entityCode: Entity code associated with this entry.
entityCodeNamespace: Local identifier of the namespace of the entity code if different than the pickListDefinition defaultEntityCodeNamespace. entityCodeNamespace must match a local id of a supportedNamespace in the mappings section.
Possible forms of Pick List Definitions
- Ability to include all the concept codes contained in the referenced value set resolution by setting completeSet flag to 'true'
- Ability to include individual pickText derived from concept code designation of the referenced code system
- Ability to exclude concept codes from the pick list
- Ability to combine of any of the above
Here are some fictitious examples of Pick List Definitions
Example 1

Example 2

Pick List Definition Versions
Pick List Definitions are versioned. The version of Pick List Definition changes when ever the definition is changed, it could be changing, adding or removing pickListEntryNode.
Pick List Services
LexEVS Pick List Services is an integral part of LexEVS Core API. It provides:
- Ability to load Pick List Definitions into LexGrid repository
- Ability to apply user restrictions and dynamically resolve the definitions during run time
- Ability to author Pick List Definition
Major functions provided by Pick List Services
- Administration functions:
- Ability to load Pick List Definitions into LexGrid repository.
- Ability to remove Pick List Definitions from LexGrid repository.
- Here are some of the admin methods available:
- loadPickList(PickListDefinition pldef, String systemReleaseURI) - Loads supplied Pick List Definition object
- loadPickList(InputStream inputStream, boolean failOnAllErrors) - Loads Pick List Definitions found in inputStream
- loadPickList (String xmlFileLocation, boolean failOnAllErrors) - Loads Pick List Definitions found in input xml file
- removePickList(String pickListId) - Removes supplied Pick List Definition from the system
- Query functions:
- Ability to list all the Pick List Definitions loaded in the system.
- Ability to dynamically resolve Pick List Definition with/without user supplied restrictions.
- Ability to list all the Pick List Definitions that uses given Value Set Definition URI.
- Here are some of the query methods available:
- getPickListDefinitionById(String pickListId) - Returns pickList definition for supplied pickListId
- getPickListDefinitionsForValueSetDefinition(URI valueSetDefinitionURI) - Returns all the pickList definitions that represents supplied value set definition URI
- getPickListValueSetDefinition(String pickListId) - Returns an URI of the represented value set definition of the pickList
- listPickListIds() - Returns a list of pickListIds that are available in the system
- resolvePickList(String pickListId, boolean sortByText) - Resolves pickList definition for supplied pickListId
- resolvePickListForTerm(String pickListId, String term, String matchAlgorithm, String language, String[] context, boolean sortByText) - Resolves pickList definition by applying supplied arguments
- ResolvedPickListEntryList : Contains the list of resolved Pick List Entries. Also provides helpful features to add, remove, enumerate Pick List Entries.
- Authoring functions:
- pickListDefinition and pickListEntryNode classes are versionable entities in LexGrid model. Following authoring functions can be performed on them:
- NEW : Create new Pick List Definition or add new pickListEntryNode to existing Pick List Definition.
- MODIFY : Modify existing attributes of Pick List Definition or pickListEntryNode.
- REMOVE : Ability to completely remove Pick List Definition or pickListEntryNode. This is not the same as deprecated, as the entity ceases to exist in future versions.
- pickListDefinition and pickListEntryNode classes are versionable entities in LexGrid model. Following authoring functions can be performed on them:
Refer to Revision section of this document for information on how revisions can be applied and how LexEVS handles them.
CTS 2 specific Pick List Services
There are NO functional specifications specific to Pick List in CTS 2 SFM.
Load Scripts
Scripts to load Pick List Definitions into LexEVS system will be located under 'Admin' folder of LexEVS install directory. This loader scripts will only load data in XML file that is in LexGrid format.
Pick List Loader
LoadPickList.bat for Windows environment and LoadPickList.sh for Unix environment.
Both these scripts takes in following parameters :
-in |
Input <uri> URI or path specifying location of the source file. |
-v |
Validate <int> Perform validation of the candidate resource without loading data. |
Example:
sh LoadPickList.sh -in "file:///path/to/file.xml"
Password Encryption
Encryption is the process of taking data (called cleartext) and a short string (a key), and producing data (ciphertext) meaningless to a third-party who does not know the key. Decryption is the inverse process: that of taking ciphertext and a short key string, and producing cleartext.
LexGrid utilizes the java security API for encryption and decryption of the database passwords. The Security API is a core API of the Java programming language, built around the java.security package (and its subpackages). This API is designed to allow developers to incorporate both low-level and high-level security functionality into their programs.
The Java Cryptography Architecture encompasses the parts of the Java 2 SDK Security API related to cryptography, as well as a set of conventions and specifications provided in this document. It includes a "provider![]() "architecture that allows for multiple and interoperable cryptography implementations.
"architecture that allows for multiple and interoperable cryptography implementations.
Encryption/Decryption implementation Details:
Creating a Cipher Object
Cipher cipher = Cipher.getInstance("PBEWithMD5AndDES");
"PBEWithMD5AndDES" is the widely used algorithm used for the encryption process. Other available algorithms are "PBEWithHmacSHA1AndDESede", "AES", "Blowfish", "DES", "DESede" etc.
{*}InitializingaCipherObject*">Initializing a Cipher Object
cipher.init(<MODE>, <KEY>, <PBEParameterSpec>);
A Cipher object obtained via getInstance must be initialized for one of four modes, which are defined as final integer constants in the Cipher class. The modes can be referenced by their symbolic names, which are shown below along with a description of the purpose of each mode:
- ENCRYPT_MODE: Encryption of data.
- DECRYPT_MODE: Decryption of data.
- WRAP_MODE: Wrapping a Key into bytes so that the key can be securely transported.
- UNWRAP_MODE: Unwrapping of a previously wrapped key into a java.security.Key object.
{*}EncryptingandDecryptingData*">Encrypting and Decrypting Data
cipherBytes = cipher.doFinal(<text to encrypt/decrypt>);
Passwords in LexEVS are encrypted /decrypted in one step (single-part operation) by passing the text to encrypt/decrypt as a parameter.

Following are the steps to encrypt the password of LexEVS database.
- Run PasswordEncryptor.sh or PasswordEncryptor.bat (pass password text as a parameter) from lbAdmin to generate the encrypted password.
- Generated password will be stored in a file @ lbAdmin/password.txt
- Copy the encrypted password from password.txt and paste it in lbConfig.props file ( DB_PASSWORD=<Encrypted_Password> )
- Set the new lbConfig parameter DB_PASSWORD_ENCRYPTED=true (value case insensitive) .
- Note : any value other than 'true' (or no value) for DB_PASSWORD_ENCRYPTED is considered as 'false'.
- Note : any value other than 'true' (or no value) for DB_PASSWORD_ENCRYPTED is considered as 'false'.
- When password encryption is off, use the password directly as you have been using till now.
XML Export
XML exporter exports the LexEVS6 contents (coding scheme and components) from LexEVS database to an XML file. The output XML file will be a valid LGXML file. The process of extracting content from LexEVS is done by using LexEVS 6 APIs.
The exporter will also have the ability to export a subset of coding scheme content. Users will be able to provide criteria that will determine what content is returned. An example would be to export only associations.
The exporter will stream the content from LexEVS to the XML file. This will allow for large ontologies to be exported.
Right now the design to accomplish this is as follows:
- Read the CodingScheme object.
- Get CodedNodeSet/CodedNodeGraph from the coding scheme.
- Add a dummy entity to the coding scheme object.
- Add Entities (or associations) by applying the filter criteria –
- In the first phase of development two uses cases will be supported:
- Export the whole coding scheme
- Export only the associations of a coding scheme.
- Later, a richer set of user supplied criteria will be supported.
- In the first phase of development two uses cases will be supported:
- Construct a marshaller that will marshal the select contents in step 4.
- Create a listener that will take the CodedNoteSet, CodedNodeGraph and output file details as parameters.
- Add the listener to the marshaller.
- Marshal the coding scheme with the created marshaller. During the marshalling processes the listener will call into LexGrid to get contents to further marshal. For example, it will detect our dummy entity object and make a call to LexEVS to get a block of entity objects.
- The marshaller and listener will work together to stream the contents to the output file.
Unable to render embedded object: File (worddava7b949c685ac84a12aac73b86847dab5.png) not found.
Figure 1
Note in Figure 1, we show two Listeners. These may be combined into a single listener that will contain both the CodedNodeGraph and CodedNodeSet objects.
In Addition to this we plan to develop JUnits and other auxiliary set of resources that will be make it ready to be hooked up to DOA layer when ready.
Finally, documentation will be provided to explain how to supply filtering criteria to the exporter.
Authoring Solutions
LexEVS API and LexGrid model have been designed to provide capabilities to make changes to the terminology elements such as code system or value sets. However, the current LexGrid architecture and model is based on the premise that the information being provided is valid and consistent and is not designed to support partially formed artifacts such as concepts without associated codes, associations that have a source but no target, etc.
The LexEVS authoring tasks assumes that there is an external authoring tool that persists partially formed content and performs the necessary validation and reasoning tasks prior to their being incrementally loaded into the LexEVS services. We see this as being a necessary separation, as the potential combination of editors, reasoners, terminology models, etc. is almost limitless, and each of these will have its own requirements when it comes to completeness and validity.
LexGrid versioning model

LexGrid versioning model description
- systemRelease - A collection of coding schemes, value set definition, pick list definitions and/or revision records that are distributed as a unit.
- editHistory - An ordered collection of revisions.
- revision - An ordered collection of state changes that define the transformation of a set of resources from one consistent state to another.
- changeAgent* - The local identifiers of the source that participated in this particular change. changeAgent must match a local id of a supportedSource in the corresponding mappings section.
- changeInstructions - A human or machine readable set of instructions on how to apply this change.
- revisionId - The unique identifier of this revision.
- editOrder - The relative order that this revision is to be applied if in a systemRelease.
- revisionDate - The end date for which this version is operative (considered committed).
- Versionable - A resource that can undergo change over time while maintaining its identity.
- Owner - The owner of the resource. The specific semantics of owner is defined by the business rules of the implementer, including the rules of the owner field is absent.
- isActive - True means that this resource is searchable and browsable if the temporal context of the operation falls between effectiveDate and expirationDate. False means that this resource is only accessible if requested by id or by a search that specifies that inactive retrievals are allowed. Default: True
- status - The status code associated with the particular resource. The semantics and business rules of entryStatus are defined by the containing system, but there needs to be a mapping into isActive above.
- effectiveDate - The date and time that this resource is considered to be active. To be considered active, isActive must be true, and the temporal context of the operation must be greater than effectiveDate. If omitted, all temporal contexts are considered to be valid.
- expirationDate - The date and time that this resource is considered to become inActive. To be considered active, isActive must be true, and the temporal context of the operation must be less than expirationDate. If omitted, all temporal contexts are considered to be valid.
- entryState - Represents a change that occurred between the current state of the versionable entry and an immediately preceding state of the same entry.
- containingRevision - The revision that contains this particular entry state change.
- relativeOrder - The relative order that this state change should be applied within the context of the containing revision.
- changeType - The type of change that occurred between this state and the previous.
- NEW - Versionable entry is new in this revision. No previous state is available.
- MODIFY - Entry has been modified between this state and the previous.
- VERSIONABLE - Versionable attribute has changed since prior version. Versionable attributes include: isActive, status, owner, effectiveDate or expirationDate.
- DEPENDENT - The status of a dependent entry has changed since the last version. Dependent entities include properties, codedEntries for codingSchemes, associationInstances, etc.
- REMOVE - Versionable entry was removed as of this version. This is not the same as deprecated, as the entity ceases to exist in future versions.
- prevRevision - The unique identifier of the state of this entry was at prior to this change.
- changedEntry - A top level versionable entry. Each changedEntry bucket can contain changedCodingSchemeEntry or changedValueSetDefinitionEntry or changedPickListDefinitionEntry.
- changedCodingSchemeEntry - this element is of type codingScheme and can contain changes to terminology entities.
- changedValueSetDefinitionEntry - this element is of type valueSetDefinition and can contain changes to the definition of a given value set.
- changedPickListDefinitionEntry - this element is of type pickListDefinition and can contain changes to the definition or the pickListEntrys.
LexGrid versionable entries
Authoring can be performed on all the versionable entries in LexGrid logical model.
Here is the LexGrid model showing all the versionable entries:

LexGrid versionable entries description
- codingScheme - A resource that makes assertions about a collection of terminological entities.
- entity - A set of lexical assertions about the intended meaning of a particular entity code.
- relations - A collection of relations that represent a particular point of view or community.
- associatableElement - Information common to both the entity and data form of the "to" (or right hand) side of an association.
- pickListDefinition - An ordered list of entity codes and corresponding presentations drawn from a value set resolution
- pickListEntryNode - An inclusion (pickListEntry) or exclusion (pickListEntryExclusion) in a pick list definition.
- valueSetDefinition - A definition of a given value set. A value set definition can be a simple description with no associated value set entries, or it can consist of one or more definitionEntries that resolve to an enumerated list of entityCodes when applied to one or more codingScheme versions.
- definitionEntry - A reference to an entry code, a coding scheme or another value set definition along with the instructions about how the reference is applied. DefinitionEntrys are applied in entryOrder, with each successive entry either adding to or subtracting from the final set of entity codes.
- property - A description, definition, annotation or other attribute that serves to further define or identify a resource.
Authoring LexGrid non-versonable entries:
LexGrid model entries like 'source', 'usageContext', etc which are not versionable, can also be modified but only in context with its parent entry. And also, any values to these attributes will be totally replacing the existing values.
For example, if a coded concept 'abc' has a source 'company A, company B' and if the source 'company B' needs to be replaced by 'company C' but keep 'company A' as it is, we will need to pass in both source 'company A, company C' within concept 'abc' and have the changeType as 'MODIFY' for this concept.
LexEVS Authoring Architecture:
LexEVS Authoring API can accept changes to the terminology contents only in the form of:
- LexGrid java objects, OR
- XML file in LexGrid format.
The diagram below shows the architecture of LexEVS authoring environment.

LexEVS Authoring process:
Important: Before the changed terminology content is sent to LexEVS Authoring API to process, the client application should make sure that the contents are valid.
- The contents should either be in LexGrid XML format or a LexGrid java object.
- The entry level for the changed contents should be at either systemRelease or revision level.
- The input format will be validated against LexGrid schema for compliance. If validation fails, exception will be thrown.
- Each change request in the revision package is validated sequentially. Each individual request validation will be performed based on the premise that all requests that precede it have been applied (e.g. if there are two change requests, one to create a new coding scheme and the second to create a new entity for the coding scheme, the new entity request is validated on the assumption that the coding scheme has been created. The service may validate the entire revision or it may cease validation at any point after an error is detected - this is up to the service provider.
- If no errors are detected in previous step, the change package is submitted to the business rules "hook", which can apply additional validation, logging and error checking. If the business rules hook returns an error, no further processing is done and the result is returned to the submitter.
- If the submission passed step two, the complete set of changes will be applied to the service. If, for any reason, an error occurs, such as a network failure, a database failure, etc., the entire revision will be rolled back. Otherwise, the set of changes will be committed.
The intent of the change requests are as follows:
- NEW - to create a new versionable element
- MODIFY - to change the attributes of an existing versionable element
- VERSIONABLE - to change (or schedule a change of) the status of a versionable element within the context of the containing service.
- REMOVE - to remove a versionable element from the service. (Note that VERSIONABLE Retire should be used if the element and its history should remain)
- DEPENDENT - no changes are to be made to the named element itself, but a versionable element whose identity is dependent upon this element is to undergo a change.
Here is an example xml file containing changed coding scheme:

H2. Querying data based on version information:
LexEVS Authoring API provides ability to query terminology content based on:
- revision identifier
- specific date and time
H3. Query data based on revision identifier:
This allows users to get the state of an entity like concept code, coding scheme, pick list, etc, at the given revision.
Exception will be thrown if the revision identifier was not found in the system.
And if that entity (ex concept code) had no changes for that particular revision, the API will return the state of that entity when that revision was applied to the system.
Example:

In the above example, coding scheme 'CS1' is revised in 4 different instances R1, R2, R3 and R4 at respective dates. The query API will be able to provide the states of the versionable elements at different revisions. Example, API will be able to return the state of concept 'C1' at revision R2.
Query data based on specific date and time:
This allows users to get the state of an entity like concept code, coding scheme, pick list etc, at the give date and time.
Exception will be thrown if no data was found for given date and time.
Example:
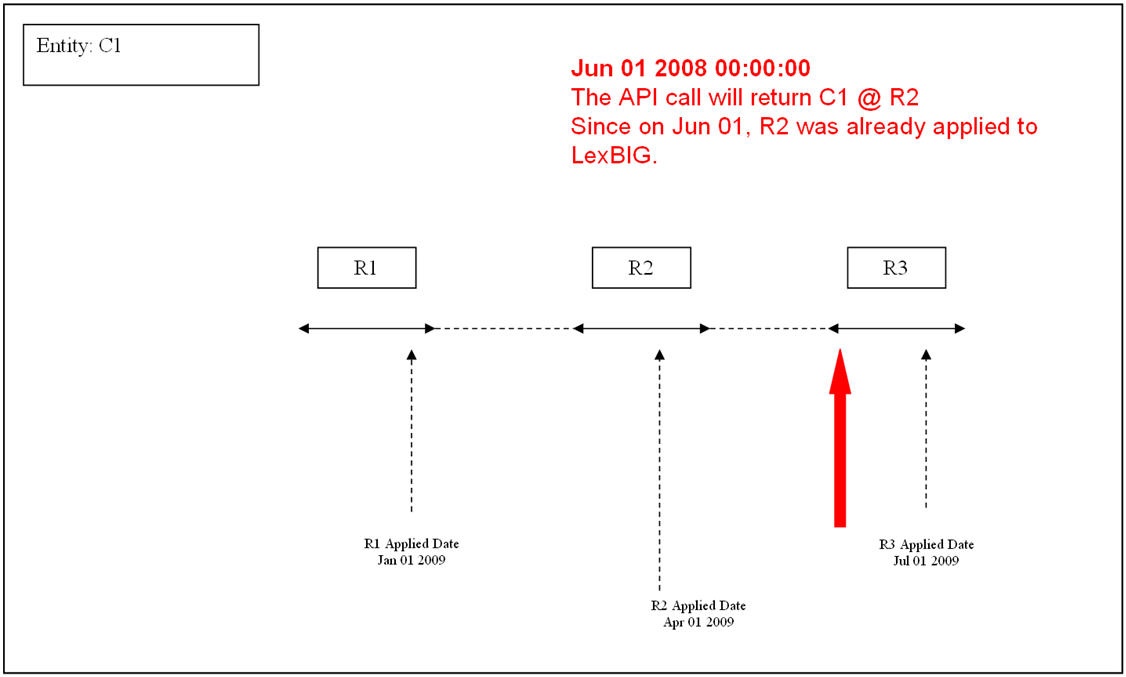
CTS 2 Authoring profile:
The CTS2 SFM calls for the ability to create, maintain and update code systems, concepts, and associations as separate entities. The LexGrid and LexEVS model views all three of them as aspects of code systems, and its incremental revision approach allows any or all of them to be changed as a single unit. The LexEVS model also subsumes the notion of a "code system supplement", as a collection of one or more revisions to a code system can be packaged as a "system release", with its own provenance, activation dates, etc., and can be applied to external code systems independently.
The Terminology Authoring Profile is intended to provide the capability to robustly query and access terminology content, as well as directly modify the terminology content. This includes the ability to modify code system content, value set content, as well as the metadata pertaining to each. This profile includes the functions necessary to administer and search terminology content as outlined in the CTS2 Query Profile as well as the Terminology Administration Profile.
Below is the list of Authoring profiles as in CTS2 SFM:
CTS2 Function |
CTS2 Function Description |
LexEVS Implementation |
|---|---|---|
Create Code System |
Create a new Code System to contain a |
LexEVS provides ability to load Code System
|
Maintain Code System Version |
Update Code System meta-data properties. |
The LexEVS Authoring services will provide |
Update Code System Version Status |
Changes the status of a code system version |
The LexEVS Authoring services will provide |
Create Code System Supplement |
Create a new Code System Supplement as a |
LexEVS treats Code System Supplement as any |
Maintain Code System Supplement |
Update Code System Supplement meta-data properties |
The LexEVS, Code System Supplement is treated |
Create Concept |
Create concept to be included in a Code System. |
The LexEVS Authoring services will provide |
Maintain Concept |
Update Concept meta-data properties. |
The LexEVS Authoring services will provide |
Update Concept Status |
Changes the status of a code system concept |
The LexEVS Authoring services will provide |
Create Association Type |
Create a new relationship type |
The LexEVS Authoring services will provide |
Maintain Association Type |
Update or deprecate an Association type that may |
The LexEVS Authoring services will provide |
Create Value Set |
Create a Value Set (extensional or intensional) |
The LexEVS Authoring services will provide |
Maintain Value Set |
Update properties or expression of a value set definition |
The LexEVS Authoring services will provide |
Update Value Set Status |
Changes the status of a value set version |
The LexEVS Authoring services will provide |
Create Concept Domain |
Create a Concept Domain. |
In LexEVS, a coding scheme can contain entities |
Maintain Concept Domain |
Update properties of a Concept Domain, including |
Similar to 'maintain concept' function described |
Create Usage Context |
Create a Usage Context. |
Similar to 'create concept domain' function |
Maintain Usage Context |
Update properties of a Usage Context |
Similar to 'maintain concept' function |
Update Association Status |
Update the status of an association |
LexEVS Authoring API provides |
Create Association |
Relates a single specific coded concept |
LexEVS Authoring API provides ability |
*Create Lexical Association |
Relates a set of one or more coded concepts |
This functionality is out of scope for this release. |
*Create Rule Based Association |
Relates a set of zero or more coded concepts |
This functionality is out of scope for this release. |
Implementation Requirements
Training and documentation requirements
One heading for each item.
Download center changes
List the needed changes.